















































































































































The APTrust Award for Resilience, Maintenance and Continuity

This award celebrates efforts that support and maintain critical infrastructure for digital preservation services and systems, ensuring the integrity and resilience of digital preservation workflows. The award includes a cash prize of £1000, a trophy and certificates.
Meet the finalists:
PRONOM refresh
 |
Nominee: Steve Daly PRONOM is a registry of file format information which underpins digital preservation workflows used by archives worldwide, but after 20+ years it faced growing technical and sustainability risks. With no dedicated funding, a small team proactively rebuilt the service using a radically-lightweight, open architecture incorporating automated testing and zero-idle infrastructure. This improved security, running costs, environmental sustainability, and delivers a highly-accessible and responsive website whilst enabling programmatic reuse of data. Delivered as a minimal-viable-product with continuous deployment, the new PRONOM secures the future of a critical community resource and redefines how registries such as this can be sustainably maintained. |
Data Integrity Application for the Everyday User: Developing and Implementing Basic Integrity Checks Applied in Abu Dhabi During Times of Regional Conflict
 |
Nominee: Rebecca Pittam To address NYU Abu Dhabi Library’s preservation needs during the 2025-2026 academic year, we developed a custom “Data Integrity Application” designed for accessibility across all expertise levels. With a click of a button, and utilizing forensic audit principles, the tool ensures data authenticity by tracking the "digital fingerprint" of every file. By democratizing complex preservation tasks for a small team of archivists and assistants, the tool served as a vital bridge between high-security servers and emergency off-site redundancy during the recent Middle East regional conflict. This initiative resulted in a successful 100% audit of two terabytes of institutional digital assets. |
CoreTrustSeal: A Global, Community-Driven Model for Trustworthy Digital Repositories
 |
Nominee: CoreTrustSeal CoreTrustSeal is an international, community-driven certification that helps verify that repository holdings are safe, reliable, and available for future use. It recognizes repositories that meet high standards for managing, preserving, and sharing digital materials through independent peer review. By earning this certification, repositories demonstrate they can be trusted to care for valuable digital materials and make them accessible to researchers and the public for the long-term. CoreTrustSeal supports open science by helping people find and reuse digital materials with confidence, strengthening research, innovation, and informed decision-making. |

Transcripción y difusión de la documentación manuscrita del archivo municipal de La Nucía mediante el uso de inteligencia artificial

Transcripción y difusión de la documentación manuscrita del archivo municipal de La Nucía mediante el uso de inteligencia artificial
Archivo Municipal de La Nucía, Guillem Chiner Betlloch
 |
 |
 |
1. Introduction
The project for the transcription and dissemination of handwritten documentation from the Municipal Archive of La Nucía is an innovative initiative that combines heritage preservation, digitisation, and artificial intelligence to facilitate access to local history. Its main objective is to transform a highly valuable but difficult-to-read documentary collection into an accessible, understandable, and useful resource for the general public.
The Municipal Archive preserves documentation dating back to the 18th century, linked to the origin of the municipality in 1705. These records are a key source for understanding the historical, institutional, and social development of La Nucía and its surrounding area. Over the years, the City Council has prioritised their preservation, particularly through the digitisation process initiated in 2018.
2. Initial situation
Before the development of the project, the archive had more than 30,000 digitised pages available through a web platform. This represented a significant step forward in preservation and access, but it did not resolve a key issue: the difficulty of reading handwritten documents.
Old scripts, abbreviations, and document deterioration made their content largely inaccessible to the general public. In practice, this limited their use to specialised researchers, reducing the archive’s social impact.
In addition, the existing web platform had technological limitations, including a non-intuitive interface and limited search tools, making both public access and internal management more difficult.
3. Solution developed
The project proposes a comprehensive solution based on two main pillars: the application of artificial intelligence and the technological renewal of the archive.
On the one hand, an automated transcription system for handwritten texts has been implemented using probabilistic indexing techniques. This technology converts document images into readable text, facilitating understanding and enabling full-text search.
On the other hand, the archive’s web platform has been completely redesigned, providing a modern, accessible, and user-friendly interface. The new portal allows easy navigation and access to both digitised documents and their transcriptions.
The renewed archive can be accessed at:
http://arxiumunicipal.lanucia.es/
A dedicated platform for consulting AI-transcribed documents is also available at:
https://transcripcions.lanucia.es/la_nucia/
4. Project development
The project has been implemented progressively, prioritising the documentary collections of greatest historical and administrative value.
To date, approximately 10,000 pages of handwritten documents have been indexed and transcribed, out of more than 30,000 digitised pages. This first phase has focused on the series of Municipal Council Minute Books.
This is the most important documentary series in the archive, as it records all decisions taken by the City Council since its foundation. These documents provide a detailed account of public decision-making over time, making them a key resource for both research and administrative purposes.
5. Results and achievements
The project has significantly transformed access to the municipal archive.
Firstly, it has removed one of the main barriers to access: the difficulty of reading handwritten texts. Thanks to automated transcription, any user can now understand documents that previously required specialised knowledge.
Secondly, it has introduced full-text search capabilities, greatly enhancing research and consultation possibilities.
Furthermore, the new web platform has considerably improved the user experience, enabling fast and intuitive access to information.
Finally, the project represents a real example of the application of artificial intelligence in public administration, demonstrating its value in cultural heritage management.
6. Social and cultural impact
The project has a particularly strong social and cultural impact. By facilitating access to historical documentation, it democratises knowledge and brings the archive closer to the public.
The archive is no longer a resource limited to specialists but becomes an open tool for students, residents, and researchers. This encourages interest in local history, strengthens collective identity, and promotes knowledge of the municipality’s roots.
It also creates new educational opportunities, enabling the archive to be used in schools and training activities. Additionally, it fosters local research and citizen engagement with the past.
From an institutional perspective, the tool allows efficient retrieval of relevant historical information, supporting municipal management, particularly in matters related to past decisions or heritage.
7. Future outlook
The project has a clear long-term vision. The 10,000 pages already transcribed represent the first phase of a broader process that will eventually cover the entire archive.
Further dissemination, training, and engagement activities are planned to maximise the archive’s social impact and consolidate its role as a reference in innovation applied to documentary heritage.
8. Conclusion
This project represents a major step forward in the modernisation of the Municipal Archive of La Nucía. Its main achievement is transforming a historical documentary collection, traditionally difficult to access, into an open, understandable, and useful resource for society.
By combining digitisation, artificial intelligence, and technological renewal, the project not only preserves heritage but also makes it accessible and relevant in the present.
Ultimately, it is an initiative that connects past and future, demonstrating how innovation can serve culture, public administration, and society as a whole.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
PRONOM refresh

PRONOM refresh
Sam Palmer, Steve Daly, Andrew Hosgood
| |
 |
 |
PRONOM is an important registry of file-format information and format identification signatures which is used heavily across the Digital Preservation community and relied upon to underpin the operation of tools such as DROID, Siegfried, FIDO and many commercial products. It also provides a user interface to allow archivists to research the formats in their collection and consider how to maintain their long-term accessibility.
PRONOM was developed by The National Archives (UK) who support it and administer the contribution, testing, and release of format identification signatures developed by experts across the wide community, as well as researching new format information and signatures in-house.
The PRONOM database, process and website have not had any significant development in over 20 years and all these elements are becoming increasingly difficult to support and keep secure, accessible, sustainable, and available - putting the continued existence of this valuable resource at risk. Support for the application is spread across various legacy components owned by multiple teams within The National Archives (TNA) and each release requires a complex coordination activity.
Although there has been a desire for many years to give attention to PRONOM, with limited budgets there are no staff within TNA devoted purely to developing tools such as DROID and PRONOM, nor to undertaking file format research and signature release activities. This work is delivered alongside other responsibilities, which does give a significant positive benefit of keeping the maintainers of these tools connected to real-world challenges arising from business-as-usual operations.
But it wasn’t possible to secure funding or resource for any significant work on PRONOM during 2025/26 due to critical business priorities such as the migration of the records of The Parliamentary Archives to TNA, and replacing core digital repository systems.
However, a small group of people felt strongly about this challenge and found spare time alongside other commitments to deliver a new version of PRONOM during 2025/26.
Rather than simply undertake a like-for-like monolithic refresh of the application, we wanted to bring both the architecture and principles up to date for the modern age. The new PRONOM needed to be trivial to support and administer; with a minimal environmental footprint; be 100% open source; intrinsically secure; support easy third-party access to the data; operate with a minimal cost; enable community contributions to both the file-format data and the application; be deliverable with minimal resource; and facilitate agile development and continuous deployment to keep pace with rapidly changing requirements. Whilst still being backwards-compatible with every version of DROID still in service!
Key aspects of PRONOM workflows include managing third-party contributions; complex regression testing; managing releases of signature sets; controlling user access for data modification and maintaining audit histories. These are also all functions critical to modern software development activities and so we decided to make use of existing software development tooling for the core functions of the new PRONOM.
Therefore, all these aspects of PRONOM are now undertaken by the source code control system “GitHub”. The PRONOM ‘database’ is no longer a complicated relational database, but is simply a set of JSON files stored in GitHub here https://github.com/nationalarchives/pronom
User-management is handled by GitHub; testing is fully automated; and releases of file format signature sets are managed by GitHub’s release process which use GitHub Actions for automated testing. It will be significantly easier for archivists to maintain the data within the new PRONOM and to deliver regular releases.
The new PRONOM website runs very efficiently using serverless cloud technologies. When no-one is accessing the site, it consumes zero energy with zero cost. There are no servers running to maintain PRONOM - resources are only used on-demand. Due to heavy caching and pre-rendering of pages, the incremental cost from user access is minimal too. The site is built using Infrastructure-As-Code (IaC) technologies which assists with business continuity and disaster recovery. Although data is hosted in GitHub, TNA do hold additional copies.
The new PRONOM is delivered initially as a Minimal Viable Product and intentionally does not replicate every feature of the previous system, however there has been a heavy focus on user engagement and, due to using modern software development and deployment practices, features can trivially be added and deployed immediately. Recent requests for feature enhancements were all delivered and deployed the same day. We have some enhancements designed but not yet deployed, for example around self-service user submission of signature information, but have launched intentionally with a minimal viable solution.
Currently the site is dual-running with the old PRONOM, but under the new address of https://pronom.nationalarchives.gov.uk promoting the system to a more prominent domain name within TNA. The previous address will be kept live for access by existing DROID applications, but will soon point to the new PRONOM once we are comfortable that all essential features are delivered by the new product. DROID users won’t notice any change.
The new PRONOM makes use of TNA’s highly-accessible and responsive web templates and we are pleased with the usability and accessibility improvements this brings over the previous system. A user survey is offered to all users to gather feedback for continuous improvement to the product.
Using serverless technologies brings a natural improvement in security posture due to there being no need for operating-system patching and updates, however this new application benefits from a range of security tools such as continuous code analysis, cloud security posture management and cloud detection and response. Independent penetration testing has been undertaken on the system before launch.
A significant issue with the previous PRONOM was that the underlying data was not programmatically accessible outside of TNA without scraping our website, however as all data underpinning the new PRONOM is available publicly via GitHub, anyone wanting to make use of this data can access it directly in whatever ways they require.
We are all very pleased with the results of this work and feel that this sets PRONOM up for many further decades of giving value to the Digital Preservation Community and introduces a design pattern for how such registries can be sustainably maintained.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
AN OAIS-COMPLIANT ARCHIVING PLATFORM WITH DNA CONNECTOR WITHIN OLOS
AN OAIS-COMPLIANT ARCHIVING PLATFORM WITH DNA CONNECTOR WITHIN OLOS
Pierre-Yves Burgi, Hugues Cazeaux, Dario Genga, Michaël El Kharroubi, Florient Serex, Jérôme Charmet
 |
 |
 |
In accordance with the principles of OAIS-compliant repositories (ISO 14721), OLOS (olos.swiss) offers an open, Core Trust Seal certified, and modular architecture for the long-term preservation of data in the fields of public administration, cultural heritage and research. Once deployed in the cloud, these independent modules offer a range of services enabling users to prepare their archives for preservation, namely: to submit them via a pre-ingest step followed by ingestion (submission package - SIP), to store them physically (archival package - AIP), to index metadata (represented in standard formats such as the METS container with PREMIS and DataCite fields) and to access them (dissemination package - DIP) based on specific rights and data sensitivity. This suite of services guarantees both the implementation of best practices in the field, such as virus detection, format detection, checksum calculation, integrity verification, replication, etc. – and tight integration with other information systems and all types of storage media, including those based on biotechnology.
As part of the DNAMIC project (dnamic.org), which is funded by the European Pathfinder program, we have developed a DNA connector that interfaces OLOS with a micro-factory capable of autonomously processing DNA, from synthesis to sequencing, thereby enabling the autonomous storage of data into DNA. Thanks to its extremely high data density (hundreds of petabytes per gram), longevity (thousands of years with minimal degradation), and sustainability (very low energy consumption), the use of DNA is set to revolutionize archival preservation. As long as there is life, humanity will have mastery over DNA, therefore, there will be no risk of technological obsolescence, unlike with magnetic and optical systems.
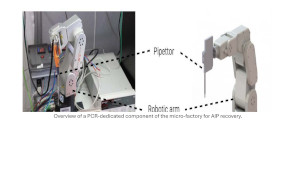
To archive documents in synthetic DNA, once they have been imported into OLOS, the AIPs are processed via the DNA connector. The DNA connector, using an encoder/decoder (aka CODEC), first encodes the binary AIP into a DNA representation, then sends it to the micro-factory, which distributes the genomic tasks among the relevant modular devices. DNA is composed of four bases, namely the nucleotides adenine, thymine, cytosine, and guanine, designated by the letters A, T, C, and G, respectively. To represent the information contained in DNA, a coding step is therefore necessary to convert a binary representation into a quaternary base system. A simple coding consists, for example, of associating the binary codes 00 with A, 01 to C, 10 to G, and 11 to T. Without going into detail, several types of encoding are possible, but they must consider biological constraints, such as avoiding successive repetitions of the same nucleotides (""homopolymers"") or certain motifs, as well as a balanced distribution between GC and AT nucleotides (constraints that the simple coding mentioned above does not satisfy). Once assembled, the strands are processed in the micro-factory, which is capable of synthesizing DNA letter by letter to create the molecules. These molecules are then packaged in dehydrated form in vials. Since the chemical process for manufacturing synthetic nucleotides has a relatively low error rate for segments shorter than 300 nucleotides, the binary files are segmented to comply with this limit. To enable the files to be reconstructed after sequencing, each segment is associated with an index, encoded within the structure of the nucleotides. Redundant error-correction information is also added. Finally, each strand of DNA belonging to a given AIP is assigned two additional DNA strands specific to that AIP at both ends. These strands, called ""primers,"" are used to uniquely identify the AIPs contained in the vials.
To read an AIP contained in a vial, the synthesizer first produces primers specific to that AIP. The micro-factory uses a micro-pipette to collect a DNA sample, which is then transferred to the amplification (or ""PCR"") unit. The strands amplified by the primers are then divided into two sets. One is sent back to the DNA storage unit for future use, and the other is sent to the sequencing stage. In the designed micro-factory, sequencing relies on the latest nanopore technology, which has the advantage of being compact and affordable but has a relatively high read error rate (around 5% to 10% on average). Upon exiting the sequencer, the reads are then decoded by the CODEC. Several steps are devoted to correcting potential errors involving nucleotide insertions, deletions, or substitutions before reorganizing the reads according to their index to reconstruct the binary file. The latter is then sent back to OLOS to be distributed in DIP format.
To evaluate the entire OAIS cycle, from the SIP through the encoding of the AIP into the four DNA molecules, and finally the delivery of the reconstructed DIP, we prepared several test files with different redundancy profiles. In silico samples were prepared using a sequencer noise model. For in vitro sampling, we obtained DNA strands using various synthesis and sequencing technologies. Preliminary results, based on in silico and in vitro analyses, demonstrate the potential of our approach to handle high error rates (up to 20%) and decode 1-megabyte files in less than 5 minutes. In these experiments, decoding is considered successful only when the AIP checksum is verified. While a single vial could store hundreds of petabytes, the prototype currently in production operates on the megabyte scale; however, optimizing encoding/decoding (CODEC) and other processes will allow us to expand this capacity far beyond that. We therefore aspire to create more scalable DNA data storage solutions, thereby making a significant contribution to the future of digital archiving methods.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
EOSC EDEN Core Preservation Processes (CPPs)
EOSC EDEN Core Preservation Processes (CPPs)
Members of EOSC EDEN T1.2 Core Preservation Process writing team: Micky Lindlar (WP1 Lead), Bertrand Caron (T1.2 Lead), Juha Lehtonen (Technical Coordinator), Maria Benauer, Johan Kylander, Kris Dekeyser, Matthew Addis, Mattias Levlin, Mikko Laukkanen, Felix Burger, Tiina Koho, Franziska Schwab, Laura Molloy, Fen Zhang
 |
 |
 |
The first questions when starting in digital preservation are often “What needs to be done?” and “How can I get started?” Many guidance documents, frameworks or standards address digital preservation from various angles. Standards like the “Reference Model for an Open Archival Information System” (OAIS, ISO14721) or certification frameworks like “CoreTrustSeal” offer insight into digital preservation concepts and requirements from an organisational point of view. The “NDSA Levels of Preservation” or the “Core Requirements for a Digital Preservation System” from the DPC Procurement Toolkit provide checklists to assess the maturity of systems. Registries like COPTR (the Community-Owned Digital Preservation Tool Registry) help with finding tools for specific tasks. But how should these processes be implemented? And what do they look like in detail?
Until recently, such a point of reference was missing. Our contribution, the Core Preservation Processes (CPPs) are a set of 30 processes that every digital archive should undertake - either directly or through an associated party or service - in order to fulfill its preservation mission. Identified and described within the EOSC EDEN project, the CPPs aim to provide practical implementation guidance for digital preservation processes and workflows.
We designate them “core” preservation processes because their scope covers operational activities specific to digital preservation, the core of EOSC EDEN’s contribution. As such, the CPPs do not cover strategic/managerial digital preservation activities (like staffing) nor the whole list of activities of a generic information management system, including secure IT infrastructures. Digital preservation practitioners working Task 1.2 of the EOSC EDEN project wrote the CPPs to address the widest possible digital preservation audience. They come out of a thorough comparison of widely used digital preservation frameworks, including the DPC Procurement Toolkit, the CoreTrustSeal requirements, the NDSA Levels of Preservation and ISO16363 (Audit and certification of trustworthy digital repositories).
The CPPs are available in form of three resources:
(1) EOSC EDEN M1.1 - Report on Identification of Core Preservation Processes (Zenodo publication: https://doi.org/10.5281/zenodo.16992451 )
This 363-page-long publication consists of the 30 CPP description documents as well as a Report on the Methodology, a CPP Template to allow for extensibility of the CPPs, and a Glossary that describes the conceptual model, the relationship taxonomy, as well as policies and other terms used throughout the CPP description documents.
This resource is ideal for those who wish to inform themselves about the CPP genesis, learn more about shared concepts and policies across the CPPs or have a concrete process in mind they would like to read up on. The record will be versioned as the CPPs are extended through the community.
(2) EOSC EDEN WP1 CPP Descriptions (github repository: https://github.com/EOSC-EDEN/wp1-cpp-descriptions )
In addition to the Zenodo publication, the CPPs have been published on a github repository. The CPPs are intended to be a living resource, which should be updated with new reference implementations and use cases. A discussion forum was added to the github repo to enable community interaction. In addition, new work on the CPPs, such as an alternative XML representation of the textual descriptions, can be followed and commented on.
This resource is ideal for those who wish to join the discussion or contribute to the CPPs. From here, new versions will be pushed to Zenodo.
(3) EOSC EDEN WP1 CPP Visualisation Tool (hosted version: https://cpp.fd-dev.csc.fi/ , github repository: https://github.com/EOSC-EDEN/wp1-cpp-visualization)
Where the publication offers a linear entry into the CPPs, the visualisation tool shows how the CPPs are connected to each other. It is a visual representation of the relationship model described in the glossary and instantiated in every core preservation process description. Users can drill down to individual CPPs and explore procedural or logical relationships as well as dependencies.
This resource is ideal for those who wish to explore workflows that connect different processes or learn how a CPP fits into the larger digital preservation picture.
The list of CPPs covers the following processes:
● CPP-001 Checksum Generation and Recording
● CPP-002 Checksum Validation
● CPP-003 Integrity Checking
● CPP-004 Data Corruption Management
● CPP-005 Identifier Management
● CPP-006 AIP Batch Export
● CPP-007 Virus Scanning
● CPP-008 File Format Identification
● CPP-009 Metadata Extraction
● CPP-010 File Format Validation
● CPP-011 Replication
● CPP-012 Risk Mitigation
● CPP-013 Object Management Reporting
● CPP-014 File Migration
● CPP-015 Emulation and Rendering Tools
● CPP-016 Metadata Ingest and Management
● CPP-017 Disposal
● CPP-018 Community Watch
● CPP-019 Data Quality Assessment
● CPP-020 Rights Management
● CPP-021 AIP Versioning
● CPP-022 Significant Properties Definition
● CPP-023 Risk Definition and Extraction
● CPP-024 Enabling_Discovery
● CPP-025 Enabling Access
● CPP-026 File Normalisation
● CPP-027 File Repair
● CPP-028 Creation of Derivatives
● CPP-029 Ingest
● CPP-030 Refreshment
The 30 CPP description documents share a strict structure. The “Description” section includes Inputs and Outputs, Definition and Scope, Rationale and Worst Case Scenarios as well as actual process description for each CPP. The process description includes a list of events that induce the process (trigger events) as well as a step-by-step description in a procedural and practical hands-on manner. The step-by-step description follows the SIPOC (supplier, input, process, output, customer) logic.
The “Dependencies and relationships with other CPPs” section describes dependencies and relations (logical and procedural) using a stringent taxonomy, which is described in the accompanying CPP glossary publication.
In the “Links to frameworks” section, the CPPs are mapped to CoreTrustSeal, nestor Seal and ISO 16363 sections. This enables readers to see where their own process documentation can be used in certification processes. Additionally, the CPPs have been mapped to OAIS and PREMIS
Lastly, the “Reference Implementations” section contains links to use cases and publicly available documentation for implementations of the CPP. Within the scope of the project, these references are limited to links provided by project institutions. Through github a mechanism has been introduced to allow the wider community to add new use cases and links to reference implementations.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
GOG Preservation Program

GOG Preservation Program
GOG Team
 |
 |
 |
The Scale of the Problem
The Video Game History Foundation estimates that 87% of video games released before 2010 are no longer commercially available. Books and films from the same era remain accessible through established archives, libraries, and distribution channels. Video games do not share that infrastructure. They are software, and software degrades. Operating systems evolve, hardware architectures change, and graphics APIs get retired. A game built for Windows XP may crash on Windows 11. Nothing in the game itself changed; the system it depended on moved on. Without someone doing active technical work, playable access to these works disappears title by title.
What GOG Does
GOG is a PC digital distribution platform, founded in 2008, with a long-standing focus on making older titles run on current hardware. The GOG Preservation Program, launched in November 2024, turned this into a formal public commitment. Every title that enters the Program gets tested, fixed where necessary, and maintained on an ongoing basis. GOG funds this work from its own engineering resources. The original publishers and developers are often no longer involved with these titles.
When a game enters the Program, GOG's Technical Production Team evaluates it against current Windows environments and applies whatever fixes the title needs. The scope of work varies widely. Some titles need minor adjustments: installer rebuilds, cloud save integration, and configuration tools. Others demand deep engine-level intervention. GOG's engineers rebuild rendering pipelines for modern GPUs, implement widescreen and high-resolution support that never existed in the original release, rewrite controller input systems, and fix stability issues that have persisted for decades.
A Concrete Example
Cold Fear, a 2005 survival horror title, shows what this preservation work looks like in practice. GOG's restoration, completed in November 2025, included full Windows 10/11 compatibility, native widescreen output with support up to 4K resolution, rebuilt controller support with wireless play and vibration, repaired video playback and title screen audio, and resolution of multiple crash-causing bugs at the engine level. The result was the original game made properly functional again, preserved in its intended form while running on current hardware. The game had been commercially unavailable; GOG worked with the rights holder, Atari, to bring it back to market in this restored state.
This pattern of combining technical restoration with legal and commercial work to return titles to availability runs across the entire Program. Dino Crisis, Breath of Fire IV, and the original Resident Evil trilogy had all been unavailable on PC for years before GOG negotiated their return and applied preservation work to each.
Scale and Growth
GOG launched the Program with 100 titles in November 2024. By February 2026, the count had grown to 267 titles with over 1,460 individual preservation improvements applied: compatibility fixes, restored content, stability patches, and quality-of-life enhancements. Each title in the Program has a public preservation log documenting the specific changes GOG's team made, providing transparency about what was done and why.
All titles in the Program ship DRM-free. Users receive standalone installers they can store, back up, and run independently of any online service. If a platform shuts down, the software keeps working. Users do not depend on a server remaining online to access their games. This is a deliberate preservation design choice.
Ongoing Maintenance
The GOG Preservation Program is not a one-time restoration effort. GOG maintains compatibility as operating systems and hardware continue to change. When a new Windows update breaks a title, GOG's team investigates and patches it. There is no planned end date. The scope of work grows with each new title added and each new system update released.
This ongoing commitment separates the Program from typical digital retail, where older titles are often sold with no guarantee of functionality on current systems. The maintenance dimension is also what makes this a preservation initiative rather than a distribution one: GOG's responsibility extends beyond the point of sale.
Industry Context and Collaboration
GOG's preservation work connects to broader institutional efforts. In 2025, GOG joined EFGAMP (the European Federation of Game Archives, Museums and Preservation Projects) and was elected to its board, making it one of the few commercial entities sitting alongside museums, academic archives, and national collections in the organized preservation community. GOG received the Checkpoint Award 2025 for its preservation activities and organized a dedicated game preservation panel at GDC 2026, the industry's largest professional conference.
In December 2025, GOG publicly launched GOG Patrons, a voluntary support program where users contribute directly to preservation efforts. This added a community funding mechanism alongside GOG's commercial model, acknowledging that preservation work often costs more than game sales alone can cover.
Why This Matters
Video games generate more revenue than film and music combined, yet the infrastructure for preserving access to them trails far behind what other cultural forms have built. Most preservation discussion centers on archival storage of code and assets. GOG addresses a different layer: access. The Program makes sure preserved games can be played, purchased, and experienced by the public, on current hardware, without specialist knowledge or obsolete equipment.
The GOG Preservation Program shows that a commercially sustainable model for active digital preservation can work. It combines engineering, rights negotiation, community participation, and long-term maintenance in a way that keeps cultural works accessible as playable software.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
IIM Africa Digital Preservation Capacity Building and Collaboration Initiative

IIM Africa Digital Preservation Capacity Building and Collaboration Initiative
Institute of Information Management (IIM) Africa
 |
 |
 |
Across Africa, the rapid growth of digital information has not been matched by equivalent capacity to preserve it. Governments, institutions, and businesses increasingly rely on digital records, yet many lack the skills, systems, and frameworks required to ensure these assets remain accessible, reliable, and usable over time. This creates a significant risk of digital loss, weakened accountability, and reduced institutional memory.
The Institute of Information Management (IIM) Africa Digital Preservation Capacity Building and Collaboration Initiative was established to address this challenge by developing a sustainable, scalable approach to digital preservation through professional training, certification, and strategic partnerships.
At the core of the initiative is a comprehensive capacity-building model that integrates digital archiving, data governance, and data protection into structured professional development programs. These include certification programmes such as the Certified Data Protection Officer (CDPO), specialized training in Digital Archiving and Preservation, and targeted capacity development for Education Management Information Systems (EMIS) officers. Through these programmes, participants are equipped with practical skills to manage digital records across their lifecycle, from creation and storage to preservation and long-term access.
A defining feature of the initiative is its emphasis on real-world application. Training is designed not only to raise awareness but to enable implementation within institutions. Participants are guided on how to establish records management systems, develop policies, and adopt standards that support the integrity, authenticity, and accessibility of digital information over time. This ensures that digital preservation is not treated as an abstract concept, but as a practical and necessary component of modern information management.
The initiative has also been driven by a strong commitment to collaboration. IIM Africa has built a multi-country, multi-sector network involving government agencies, academic institutions, private sector organizations, and professional bodies. In Nigeria, the Institute has worked extensively to strengthen professional capacity and influence policy direction in information management and data governance. In South Africa, collaboration with local partners has led to the development of a Centre of Information Management (CIM), designed to provide structured training and certification in digital preservation and related disciplines. Additionally, the initiative is expanding into Europe, with emerging partnerships aimed at knowledge exchange and global alignment.
Through these collaborations, the initiative has created a platform for shared learning, resource exchange, and coordinated action. This cross-border approach ensures that best practices in digital preservation are adapted to local contexts while maintaining alignment with international standards. It also enables institutions to learn from one another, strengthening the overall resilience of digital information systems across regions.
The impact of the initiative is reflected in both its scale and outcomes. Hundreds of professionals across multiple countries have been trained through IIM Africa’s programs, many of whom are now applying their knowledge within their organizations. Institutions that previously lacked structured approaches to managing digital records are beginning to adopt policies, frameworks, and systems that support long-term preservation. The initiative has also contributed to increased awareness among senior decision-makers about the importance of safeguarding digital assets, leading to stronger institutional commitment to digital continuity.
One of the key strengths of the initiative is its integrated approach. Rather than treating digital preservation as a standalone activity, it is embedded within broader frameworks of data governance and information management. This ensures that preservation is considered from the point of data creation, reducing the risk of information loss and improving long-term accessibility. By linking preservation with compliance, accountability, and operational efficiency, the initiative makes a compelling case for organizations to invest in sustainable information practices.
The initiative also demonstrates innovation in how digital preservation is delivered in emerging contexts. By leveraging professional certification, modular training, and partnerships, IIM Africa has created a model that is both scalable and adaptable. It addresses resource constraints by focusing on human capacity and institutional frameworks, rather than relying solely on expensive technological solutions. This makes it particularly relevant for developing economies where infrastructure may be limited but the need for digital preservation is urgent.
Sustainability is a central consideration. The initiative is designed to continue growing through ongoing training programmes, expansion of partnerships, and the development of new centres of excellence. By building a pipeline of skilled professionals and fostering institutional commitment, it ensures that the gains made are not temporary but contribute to long-term transformation.
In summary, the IIM Africa Digital Preservation Capacity Building and Collaboration Initiative represents a significant contribution to advancing digital preservation in Africa and beyond. Through training, advocacy, and collaboration, it has addressed critical gaps in skills and awareness, empowered professionals and institutions, and laid the foundation for more resilient and sustainable digital information systems. Its integrated, scalable, and collaborative approach makes it a strong candidate for recognition as a leading initiative in outreach, advocacy, and partnership within the global digital preservation community.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
Future Nostalgia: Safeguarding the knowledge of floppy disks
Future Nostalgia: Safeguarding the knowledge of floppy disks
Project Lead: Leontien Talboom Project partners: Digital Preservation Coalition, the Centre for Computing History, Conservation Department Cambridge University Library.
 |
 |
 |
Future Nostalgia: Safeguarding the knowledge of floppy disks began with a practical challenge. While working as a technical analyst with floppy disks at Cambridge University Library, it quickly became clear it was difficult to know how to start extracting and preserving floppy disk data. Existing guidance was often fragmented, highly technical, or focused on specific tools, and it was not always clear how to recognise whether a process had been carried out correctly. This uncertainty made even basic tasks feel challenging.
Conversations with colleagues and practitioners in other institutions confirmed that this was not an isolated experience. Many organisations held floppy disks but faced similar barriers: limited documentation, reliance on specialist knowledge, and uncertainty around workflows. While resources such as The Archivists' Guide to KryoFlux provide valuable technical guidance for specific tools, they do not encompass the wider range of knowledge needed to work confidently with floppy disks, including handling, cleaning, troubleshooting, and decision-making across different contexts.
The project emerged from this need. Its aim was not only to preserve the data stored on floppy disks, but also to capture and share the knowledge required to access it in a more holistic and approachable way. The central output, the Copy That Floppy! Guide, brings together practical experience, community knowledge, and experimental work into a single, open-access resource.
Collaboration was central from the outset. An initial workshop, organised in partnership with the Digital Preservation Coalition (DPC), helped define the scope of the project and identify key challenges faced by practitioners (a summary of the workshop was published here: https://digitalpreservation-blog.lib.cam.ac.uk/diskettes-and-discussions-what-we-learned-from-the-future-nostalgia-workshops-021d51e4344e). This partnership continued throughout the project, including support for the Festival of Floppies event (described below) and the long-term hosting and maintenance of the guide, helping to ensure its sustainability beyond the life of the project. The final launch event, Copy That Floppy! LIVE, was also hosted by the DPC as a way of celebrating the publication of the guide and sharing it with the wider community.
A key focus of the project was capturing knowledge that is often informal and experience-based. Interviews with retro-computing enthusiasts and practitioners provided insight into the realities of working with legacy computer hardware; what tends to go wrong, how to troubleshoot issues, and how to recognise when processes are working as expected. These interviews have been integrated into the guide, but are also openly accessible on the Cambridge Research Repository (https://www.repository.cam.ac.uk/items/154ad280-7c47-49eb-9cbf-24b6762f6c1c, and https://digitalpreservation-blog.lib.cam.ac.uk/floppy-disks-forgotten-systems-and-fragile-knowledge-insights-from-the-retro-computing-community-b036806f5a57). This was complemented by practical experimentation carried out with the Conservation Department at Cambridge University Library, exploring approaches to cleaning mouldy disks prior to imaging (https://digitalpreservation-blog.lib.cam.ac.uk/fuzzy-logic-cleaning-floppy-disk-with-our-conservation-department-part-one-c2d3e0320a2c, https://digitalpreservation-blog.lib.cam.ac.uk/fuzzy-logic-cleaning-floppy-disks-with-our-conservation-department-part-two-4ae2bbc0e779).
The development of the guide was iterative and shaped through engagement. The Festival of Floppies (https://digitalpreservation-blog.lib.cam.ac.uk/preserving-digital-memory-at-the-festival-of-floppies-200f01092738) workshop played a particularly important role, bringing together practitioners, members of the public, and collaborators including the Centre for Computing History. This exchange created an opportunity to share approaches across different communities, with digital preservation practices informing hands-on work and vice versa. Feedback from this event, along with contributions from professional mailing lists and online forums, helped refine the guide and ensure it addressed digital preservation needs.
The project also engaged widely with the professional community. Presentations at a number of conferences, including No Time to Wait! 9 and iPRES 2025, provided further opportunities to test ideas and gather feedback.
Beyond our community, the project has attracted significant public and media interest. Coverage from outlets including BBC Future (https://www.bbc.co.uk/future/article/20251009-rescuing-knowledge-trapped-on-old-floppy-disks), NPR (https://www.npr.org/2025/10/26/nx-s1-5582312/floppy-disks-get-a-second-life-at-cambridge-university-library), and Popular Science (https://www.popsci.com/technology/floppy-disk-archivist-project/) highlights the broader relevance of floppy disk preservation and the risks associated with digital obsolescence. Public-facing events such as the Copy That Floppy Café (https://www.lib.cam.ac.uk/research-institute/events/floppy-disks-workshop), which was part of the Festival of Floppies event, further emphasised the personal value of the data stored on these media, allowing participants to recover and reconnect with their own digital histories.
The resulting Copy That Floppy! Guide is designed to be practical, inclusive, and evolving. It brings together guidance on imaging, handling, cleaning, and troubleshooting, providing a clearer starting point for those new to working with floppy disks while also supporting more experienced practitioners. Recognising that no single resource can be complete, the guide is hosted on GitHub, allowing it to be updated and expanded as new challenges, tools, and approaches emerge. There is already a recognised need for additional quick-reference materials, such as a cheat sheet, which may develop over time as the community continues to use and contribute to the guide.
Importantly, the guide is hosted by the DPC, providing a level of sustainability and ongoing stewardship that supports its long-term use. This ensures that it can continue to evolve in response to community input rather than remaining a static output.
More broadly, the project highlights an important aspect of digital preservation: the need to capture not just data, but the knowledge required to access it. By documenting workflows, challenges, and decision-making processes, Future Nostalgia contributes to a more sustainable approach to managing legacy media.
While focused on floppy disks, the project has implications beyond a single format. The challenges it addresses around uncertainty, fragmentation of knowledge, and reliance on individual expertise, are common across many areas of digital preservation. By systematically capturing and sharing practitioner knowledge in an open, collaborative way, Future Nostalgia offers a model for how communities of practice can make their expertise more accessible, reusable, and sustainable over time.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
From Basement to Citizen: An Integrated Approach to the Digitisation, Preservation and Access to Environmental Permits
From Basement to Citizen: An Integrated Approach to the Digitisation, Preservation and Access to Environmental Permits
Sofie Ruysseveldt and Ruben Van Driessche (Digital Archives Flanders)
 |
 |
 |
Local authorities in Flanders (Belgium) manage large volumes of environmental permit files, such as building permits, subdivision permits and environmental permits. These files have long‑term legal, administrative and societal value. They are needed not only while a permit is processed, but also many years later for inspections, disputes, renovations, property sales or public information requests. Historically, these records were often stored in paper archives or spread across disconnected digital systems. This made them difficult to access, time‑consuming to manage and vulnerable to loss, damage or inconsistency.
This initiative was developed to address those challenges through collaboration rather than isolated solutions. Its central ambition was to help local authorities move from fragmented, hybrid practices towards a sustainable digital way of working, without requiring each organisation to develop its own complex infrastructure. Instead of focusing on a single system or tool, the project treats digitisation, long‑term preservation and access as one coherent chain, supported by shared agreements on processes, data and responsibilities.
At the core of the approach is a central framework agreement for the digitisation of administrative documents. This agreement allows local authorities to digitise large volumes of archived paper files in a legally compliant and quality‑controlled way, without having to run individual procurement procedures. By coordinating this at a central level, expertise, standards and costs are shared, lowering the barrier for participation, particularly for smaller organisations.
Collaboration also plays a key role in how information itself is described and managed. Together, local authorities, information managers and software providers agreed on common metadata, file structures and naming conventions for environmental permit files. These shared descriptions ensure that records can be reliably found, interpreted and reused across systems, organisations and over time, reducing ambiguity and manual work.
For long‑term preservation, the project relies on the Digital Archives Flanders (DAV) E‑depot, a shared service available to local authorities and other public organisations. The E‑depot applies internationally recognised digital preservation principles and ensures that records remain authentic, reliable and accessible over time. By using a shared preservation service, local authorities do not need to maintain their own archival infrastructure, which would be costly, complex and difficult to keep up to date.
Digitised files do not enter the DAV E-depot unmanaged. A shared pre‑ingest platform supports automated and human quality control before files are accepted for long‑term preservation. This ensures that scans are complete, readable, correctly structured and correctly linked to their descriptive metadata before being stored permanently. Quality issues can be corrected early, preventing problems later in the lifecycle of the records.
A key achievement of the initiative is the direct integration between the DAV E‑depot and the permit management software used by local authorities. Through this integration, archiving is embedded directly in daily administrative processes. When a permit file reaches the appropriate stage in its lifecycle, it is transferred automatically to the digital archive, together with its metadata. This approach, known as archiving by design, ensures that preservation is not an afterthought but a natural part of the administrative workflow.
The integration also enables information preserved in the archive to be reused efficiently. Files can be consulted directly from within the permit management software, allowing staff to access archived information without switching systems. Selected documents can also be made available to citizens through existing Flemish digital platforms, such as Woningpas (Building Pass), providing transparent access to legally available information about properties.
Collaboration is central to the success of the project. Local authorities, Flemish government agencies, software vendors, digitisation providers and digital preservation experts worked together to align legal requirements, technical standards, descriptive metadata and practical workflows. This cooperation ensures that information remains consistent, trustworthy and usable across organisational and technical boundaries.
The result is a practical, end‑to‑end blueprint that local authorities can adopt step by step. It reduces administrative burden, avoids duplication of effort and improves the reliability and accessibility of permit information. Staff spend less time searching for documents or responding to information requests, while citizens benefit from clearer and more consistent access to public records.
Importantly, the initiative was designed to be reusable and extensible. Although it was developed for environmental permit files, the underlying principles - shared services, agreed metadata, controlled ingest, system integration and archiving by design - can be applied to other types of government records. Central coordination of standards and services ensures continuity over time and resilience to technological change.
By combining shared infrastructure, agreed information standards and close cooperation between partners, the project demonstrates how digital preservation can function not as a specialised back‑office activity, but as a shared public service embedded in everyday administration. It shows how collaboration enables sustainable digital preservation at scale, benefiting organisations, professionals and citizens alike.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.
LDF Recollection: Innovating a Civil Rights Archive
LDF Recollection: Innovating a Civil Rights Archive
LDF Archives Team (Shelby Wong, Ashton Wingate, Kimberly Barzola, Andrea Hill, Kayla Jenkins, Cassandra Mensah, Donna Gloeckner, Ruby Mangum, Reed Jaeger), Durable Digital (Peter Gassiraro, Alex Botteril, Shane Marsden, David Marsden, Angela Wolak)
 |
 |
 |
The NAACP Legal Defense Fund (LDF) is a nonprofit law firm spearheading the fight for civil rights since 1940. In Fall 2024, the LDF Archives launched LDF Recollection, a public digital repository containing over 13,000 digitized and described court documents, attorney working files, photographs, and oral histories. This project furthers our mission to steward and share our collection documenting the historic and ongoing struggle for civil justice and political, educational, and economic equity. Working with our partners at Durable Digital, we have innovated a digital processing workflow that supports the unique preservation, access, and security needs of a legal civil rights archive by integrating our website with archival software and a customer relations management database.
A civil rights legal collection poses inherent preservation challenges, as most of our case files, institutional records, and correspondence contain Personally Identifiable Information (PII), legally sensitive material bound by attorney-client privilege, or documentation of internal legal strategies, which may put our clients and the communities that we serve at risk. As a result, our archives were restricted to internal use and external researchers upon request, with only a small selection of records digitized. In 2020, we received a Mellon Foundation grant to lay the groundwork for large-scale digitization of our physical collections, with the aim of providing as much access as possible to our 8,000+ boxes encapsulating over 80 years of civil rights work. To our knowledge, there were no preexisting digital preservation workflows accommodating the need for legal privilege review. Additionally, the existing metadata about our collections was disorganized, at times incomplete or repetitive, and not easily consolidated into a single system.
The solution we arrived at, through close collaboration with our partners at Durable Digital, was a processing workflow integrating Preservica, a Digital Asset Management software for archival collections, and Microsoft Dynamics, a highly customizable Customer Relations Management software, to interface with LDF Recollection, which serves as the public-facing repository for digitized records. Durable Digital, a website design and digital solutions firm, helped us customize the interface of Dynamics so that we can efficiently represent and describe entity-relationships, create and manage metadata, track and manage digitization projects, conduct privilege review, and view detailed audit trails. Preservica hosts the access copies and the metadata created in Dynamics, which are made accessible based on the security category determined during the privilege review process. In compliance with the OAIS Reference Model standards, both the access and preservation copies are stored in Microsoft Azure cold storage. Dynamics enables us to consolidate and manage data on every level of organization, encompassing both physical (e.g. a physical box in a storage location) and theoretical (a conceptual collection linked to a court case) organization. This is essential because we describe all records at the item level which provides invaluable context and accessibility, although this is usually too time and labor intensive for most archives to justify. Dynamics makes item-level description possible because it allows us to cascade data from a higher to lower conceptual entities – for example, a specific attorney could be linked to one case record, and this association would then be reflected in the description of every individual item record linked to that case. As seen below on the left, the resulting workflow closely resembles a typical archival processing workflow, with the inclusion of privilege review before ingestion. Below on the right is the project management feature in Dynamics, which shows how each processing stage is not only tracked, but the appropriate research, surveying, and quality control data is also documented and stored in Dynamics. After creating descriptive metadata and privilege review, records can also be ingested directly from Dynamics into Preservica. With the launch of LDF Recollection, the Legal Defense Fund can provide public access to nearly a century of records demonstrating our efforts to combat segregation, unjust persecution, voter suppression, and other forms of social injustice historically and continually perpetuated in America. We aim to empower researchers, educational institutions, and other members of the public to discover civil rights history through primary sources in the current climate of misinformation and erasure of these histories. Our unique digital infrastructure also provides a new model for other archives and cultural institutions with legally sensitive collections, seamlessly incorporating the necessary security measures into the digitization process and streamlining description.
Our work creating Recollection was recognized by the Society of American Archivists with the Archival Innovator Award and accepted as the topic of a presentation at the Digital Library Federation Conference in 2025. With this recognition, we hope to provide a robust model for other institutions with collections that represent histories of marginalized populations, facing a similar dilemma between protecting sensitive information and sharing these materials at a time when reliable information and diverse narratives are increasingly restricted. Additionally, we do not consider these systems complete but as a foundation to continue improving and building our capacity. We are currently working on integrating born digital processing capacity into Dynamics and hope to be able to continue preserving and sharing the legacy of the fight for civil rights for future generations.
DPC Members, login to reveal the link to the voting form!
Votes must be cast online by 1200 (BST/UTC+1) on Monday 6th July.