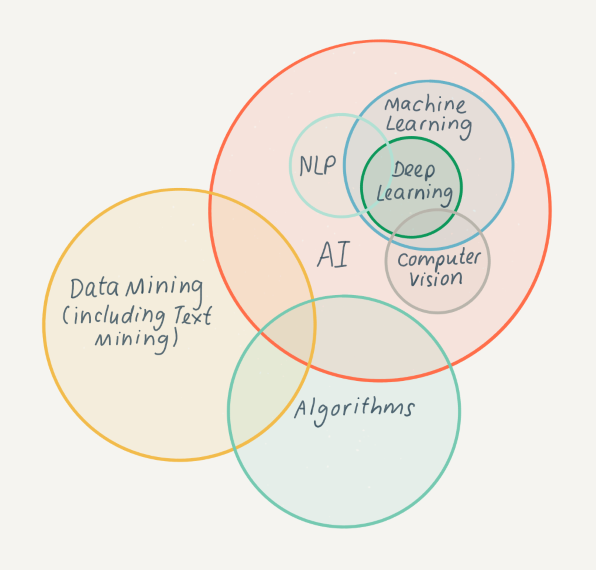
Computational access is often linked with terms such as text mining, machine learning and artificial intelligence, so much so that there is understandable confusion around what each of these concepts entails and where the areas of overlap occur. This section provides clear definitions of key terms and the relationships between them.
Computational Access
The term computational access relates to the ability to enable users to access collections within a digital preservation repository (in a machine-readable manner, e.g., via download or API) in order to analyze, interrogate, or extract new meaning from that material (through, e.g., data or text mining, machine learning) as a means of investigating a particular research question.
This term is first found in the literature in a report by HathiTrust and is closely linked to ‘Collections as Data’ which similarly urges organizations to make their collections available as data, therefore making it possible for users to compute over the material. The term is closely linked to a number of definitions, highlighted in bold above; these and other related terms are discussed below in alphabetical order.
Algorithms
An algorithm is a set of coded instructions normally followed to solve specific problems. A real-world example would be baking a cake; other examples are the process of doing laundry, or the method used to solve a logistic problem.
Artificial Intelligence (AI)
Artificial Intelligence (AI) has been defined by the UK Parliament as:
‘Technologies with the ability to perform tasks that would otherwise require human intelligence, such as visual perception, speech recognition, and language translation.’ They also add that ‘AI systems today usually have the capacity to learn or adapt to new experiences or stimuli.’ AI in the UK: ready, willing and able?
Artificial Intelligence typically takes one specific task, which would normally be done by a human, and provides a method of reliably automating it. An example of this is classifying traffic signs, or recognizing the handwriting of a particular scribe. It especially comes in handy when working with large amounts of material which are extremely time consuming to process manually. Recent developments relating to AI and archival thinking and practice are discussed in the article Archives and AI: An Overview of Current Debates and Future Perspectives.
AI can be split into Broad AI and Narrow AI, and these terms are further defined below.
Broad AI represents a system that is sophisticated and adaptive, able to perform any cognitive task based on its sensory perceptions, previous experience, and learned skills. Currently this type of AI is not achievable due to technical limitations. Read more about steps towards a broad AI.
Narrow AI is task focused. This type of AI is very good at doing one single task, for example, classifying documents into different topics. It is also referred to as Weak AI.
Sometimes Narrow AI becomes so good at a specific task that it can give the impression that it is able to think for itself, so falling under the Broad AI marker. An example of this would be the quick improvement of Voice Assistants, such as Alexa. However, current technology is only able to support Narrow AI.
More information on the differences between these two terms can be found here: Distinguishing between Narrow AI, General AI and Super AI.
Algorithms are a large component of AI, but differ slightly, as AI takes the use of these a step further. AI is basically a set of algorithms that can modify and create new algorithms in response to learned inputs and data, as opposed to relying solely on the inputs it was designed to recognize as triggers.
Computer Vision
Computer vision is a sub domain of AI that focuses on deriving meaningful information from digital images. In an archives context, computer vision could be used to generate metadata for a set of uncatalogued digital images to enable more effective processing, or search and retrieval. A good example of this can be found here: Libraries Use Computer Vision to Explore Photo Archives. As digital images can be of a complicated nature, machine learning is the methodology typically used to carry out this task. You can find out more about computer vision here: What is computer vision?
Data Mining
Data mining is the discipline of finding patterns, correlations, and anomalies in data. A broad range of techniques can be used in data mining, including AI. The data mining workflow can be roughly split into data gathering, data preparation, training, and data analysis. AI is most commonly used during the training stage; this is when the algorithm is trained in a specific task. However, as this discipline mainly focuses on using large amounts of data, AI and algorithms can also be used to aid other steps of the workflow. For example, an algorithm could be written to gather certain information from the web. Find out more about data mining here: Data Mining: What it is & why it matters
Machine Learning
Like computer vision and Natural Language Processing (NLP), machine learning is a sub domain of AI. It differs slightly from computer vision and NLP, as it focuses more on the infrastructure and models than on the techniques and material that are being inputted. Machine learning takes AI to the next level; not only are the algorithms adaptable, but they are also able to perform a task without being explicitly programmed to do so. Find out more about machine learning here: Machine learning. An example of using machine learning on archival collections can be seen on the Archives Hub blog: Machine Learning with Archive Collections.
When talking about AI and machine learning, the terms supervised and unsupervised are sometimes used. These refer to the different approaches that can be taken when applying machine learning. Supervised learning is where a labelled dataset will be used for the algorithm to learn from. A labelled dataset contains items that are tagged (mostly by humans) with an informative label; one example of this is a labelled dataset of images with names of the people who appear in them attached. Unsupervised learning uses a dataset that has not been labelled. This is the biggest difference between these two approaches, but a more nuanced explanation can be found here: Supervised vs. Unsupervised Learning: What’s the Difference?
A term that is also closely linked to machine learning is deep learning. This is a more complex form of machine learning where deep neural networks are used to resemble the complex structure of the human brain. Read more about the differences between deep learning and machine learning here: Deep Learning vs. Machine Learning – What’s The Difference?
Natural Language Processing (NLP)
NLP, just like computer vision and machine learning, is another sub domain of AI. This sub domain focuses on the ability of a computer program to understand human language as it is spoken and written. You can read more about NLP here: Natural Language Processing (NLP). Most of the time, due to the complexity of human language, machine learning will be used alongside NLP to produce better results. An example of this is text classification, where due to the ambiguous and unstructured nature of human language, this approach has only been able to evolve since the use of machine learning.
Text Mining
Text mining is very similar to data mining, the biggest difference being that instead of collecting data in general, text mining focuses solely on collecting text. Therefore, while text mining is data mining, data mining is not necessarily text mining. Text mining typically results in a large quantity of unstructured text which is difficult to analyze, so more advanced methods such as machine learning are often used in association with it to help make sense of the resulting dataset. Read more about text mining and its relationship to machine learning and NLP here: What is Text Mining, Text Analytics and Natural Language Processing?
As is apparent from the definitions as described above, there are close relationships between many of the terms used. The diagram below illustrates some of these areas of overlap.