


















































































































































Application Programming Interface (API)
Another computational access approach is the use of an Application Programming Interface (API). With this, it is possible for users to send a list of instructions within certain parameters to a data store, usually a server and a database maintained by the content provider. This list of instructions is then processed, and data is returned to the user. Further information about what an API is and how they can be used can be found here: What Is an API, and How Do Developers Use Them?. The following example from The National Archives (UK) shows how it provided an API to enable users to analyze its archival catalogue data.
Using an API is a more fluid way to access data than the bulk datasets approach, as the user can be more specific on the material that they want; it also requires less bandwidth and disk space. This is a more computational approach than the bulk datasets approach, as processing the data and updating it does not have to be done manually by the content provider – the API provides direct access to the data.
The data made available by organizations may differ; some will only opt to make their metadata available, see The National Archives (UK) Discovery API, whereas other organizations, such as The Wellcome Collection, offer access to their actual data. Documentation is mainly directed at developers wanting to use these tools. However, The National Archives (UK) offers a Sandbox mode, accompanied by a blog including examples, to make it more accessible to people with fewer computational skills.
The diagram below provides a simple illustration of how the API approach works. Data is stored in the data store (normally as a database), and the user can connect to this data store via a portal or interface.
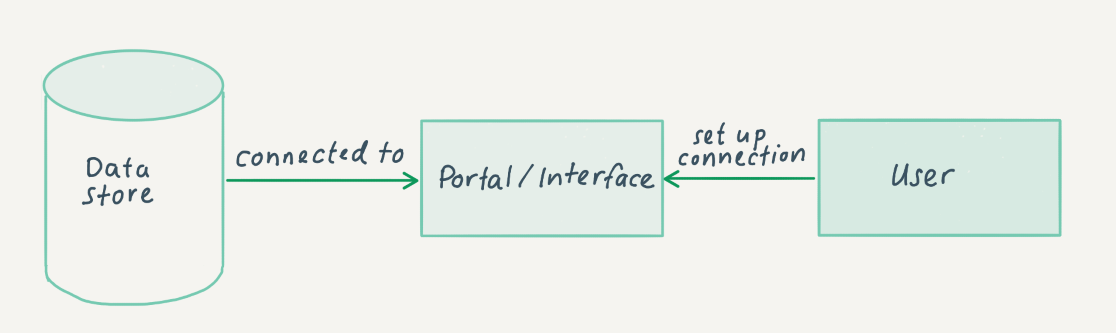
Just as with the bulk dataset approach, the API does not necessarily have to be hosted by the organization itself. Europeana offers a portal for different cultural heritage organizations and Systems Interoperability and Collaborative Development for Web Archiving (WASAPI) offers a similar idea for archived web material. APIs can have different architectural implementations. One of the most popular (also regarded as best practice) is the Representational State Transfer (REST) API. This architectural style follows a number of guidelines and has resulted in an API that is lightweight, fast and simpler by design. Find out more about REST APIs and how to use them here: Understanding And Using REST APIs.
Much of the documentation around APIs in cultural heritage institutions is unclear on their implementation; however, the WASAPI is very clear on how it has implemented and used a REST API approach and this is fully documented on GitHub. Some organizations have made a different architectural choice by including the API as an add-on to their already existing infrastructure; an example of this is the Discovery API at The National Archives (UK).
The table below lists examples of different types of APIs and describes some of the variations in their implementation, for example:
-
Does the API offer metadata or data (or both)?
-
What type of data is being offered? Is this structured or unstructured?
-
Do users have to register in order to access the API? This is a common feature of an API that may differ from other approaches (such as the bulk datasets approach). Registration to an API gives the organization an idea of who is requesting data.
|
Organization/Project |
Data/Metadata |
Type of Data |
Type of API |
Documentation |
Registration |
|
Metadata |
Structured |
As an add-on to the original infrastructure |
Yes, and includes a Sandbox mode |
The National Archives needs to be contacted and IP address should be provided |
|
|
Data |
Unstructured |
Rest API |
Yes |
N/A |
|
|
Two separate for metadata and data |
Structured |
Rest API |
Yes, but limited to developers |
No registration necessary |
|
|
Search API – for metadata and data |
Structured |
Rest API |
Yes, with multiple guides |
Registration is necessary, a new API key is needed for every implementation |