
Amy Kirchhoff and Sheila Morrissey work for the Portico digital preservation service which is part of ITHAKA, a not-for-profit organization in the USA
Portico, a service of the non-for-profit organization ITHAKA, is a preservation service for the digital artifacts of scholarly communication. Portico’s original remit 15 years ago– one shared by many DPC member organizations – was to develop a sustainable infrastructure, both institutional and technological, that would support the scholarly community’s transition from reliance on print journals to reliance upon electronic scholarly journals – more generally, to ensure that scholarly literature, published in electronic form, remains available to future generations of scholars, researchers, and students.
The occasion of the International Digital Preservation Day is an opportunity for us to reflect both on the continuing challenges (and opportunities) in preserving scholarly literature, and what we think might be new challenges ahead.
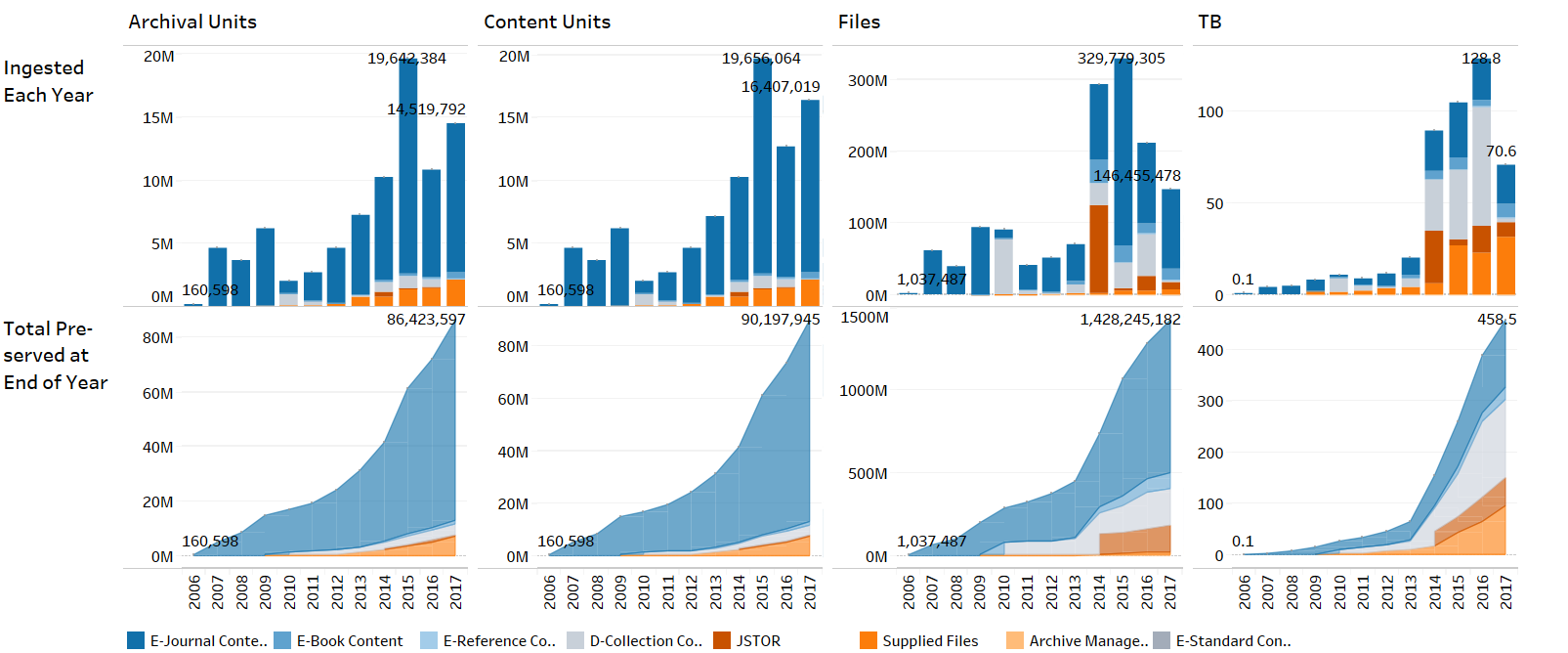
Written into our institutional DNA is the requirement simultaneously to preserve content at scale, and to preserve it in a fiscally sustainable way. Again, this is challenge we all share, across all the content domains we jointly seek to preserve. The sheer ever-increasing volume of content flowing into Portico was a major motivator for undertaking a two-year project, launched in mid-2016, to develop the next-generation Portico technical infrastructure project.
The undertaking of next-generation architectures and tools was a recurrent them at this year's PASIG conference in September. This is no surprise for digital preservationists, as one key reason we need to do the work we do is that the exigencies of the software life-cycle mean that software is ever-adapting, ever-changing, and ever-renewed (or else it is ever-gone).
The opportunity of this continual development and change is that many software tools and frameworks are now available, often as free and open source software, that make it much easier than it was fifteen years ago to construct horizontally scalable systems, running on commodity hardware (or in private or commercial clouds, or both). These tools not only make scaling easier and more reliable – they also simultaneously lower the costs of scaling, and make those on-going costs more predictable.
Increased capacity, both in volume and speed, is one of the benefits we are already seeing from the new architecture. What we also hope to realize are more sophisticated, and more completely automated, archive administration, curation, and analysis tools. We want these tools and workflows in order to provision more sophisticated monitoring and analysis of our content workflows (of interest in isolating issues that result in costly manual interventions to assure proper processing and ingest). These enriched tools and workflows will enable archive management choices, such as minimal effort ingest. We will be able to integrate and enrich our holdings and completeness tools (currently a mix of automated and manual processes), which enable us, and the scholarly community we serve, to ensure completeness of the preservation of scholarly literature, and to focus attention on capturing and preserving the long tail of scholarly literature.
The other key motivator for investing in a next-generation preservation architecture is the need we see to provision for the preservation of new, complex, and dynamic artifacts of scholarly communication, with more complex demands for acquisition, processing, and access.
What might some of those demands be?
Well, just as it was once said that “the network is the computer,” so it is increasingly clear “the network is the journal article”, or the scholarly edition. It will be, as we have described in an earlier post, a complex network of heterogeneous objects, distributed in space, any component of which may have significant versions, the relationships among components quite complex. Those components are distributed now. The likelihood is that they will be distributed in the future, some at their (more or less) original location; some in preservation repositories.
How do we provision rendition of these objects? How do we capture and represent the necessary information to connect all the nodes of the object graph? Since these are digital objects, and therefore mediated by software to provide rendition, how do we integrate tools (such as emulation) in our access services to ensure the long-term accessibility of these components?
Already, increasingly, access to scholarly materials constitutes another sort of scaling issue for preservation: the automated machine access of text and data mining. And increasingly, there are demands for datasets constructed from contents in many digital corpora, distributed across many repositories. What preparation, what normalization of content, what APIs (and tools and equipment of sufficient capacity) will be needed to provision the scholarly research of the future?
We look forward to exploring and meeting these challenges, in co-operation with our many colleagues in digital preservation around the world.