
Sheila Morrissey is Senior Researcher at Portico, based in New York
We hear again and again that, first, one of the biggest threats to ensuring long-term access to our digital heritage is the cost of preservation, and, second, that one of the critical cost drivers is the set of activities associated with selection, acquisition, and other pre-ingest processing (such as quality assurance of acquired artifacts).
As the amount of content in preservation archives grows at geometric rates, and as the artifacts in ever-increasing input streams continues to evolve, sometimes unpredictably, into varying new complex forms, how do we scale what might be called “pre-ingest” activities without scaling up our costs at the same rate?
As we noted in last year’s WDDP DPC blog post, as we at Portico were working on our “next-generation” technical infrastructure, we put quite some effort into developing new analytics services in our systems. These services automated the insurance of storage policy consistency; triggering replication; reporting on fixity failure; and triggering the disposition of redundant processing copies of content once archived and replicated. In addition, we hoped the new services would provide a framework for automating at least some of those pre-ingest processes – in particular, those associated with quality assurance of content.
The original ConPrep was modeled on some “world-as-it-should-be” assumptions:
- There would be a minimal amount of content stuck in a problem state because
- Issues would be easy to repair and could be addressed quickly and
- Publishers would be able to provide corrections to content and metadata
The reality was lots of delivered content had situations that we defined as problems (missing supplementary images, invalid XML metadata files, and so on). In many cases, what we rated as defects are not problematic situations for the publisher. In addition, if there was any flaw in any package, or batch, of content from a publisher, then all the contents in the batch were held up – that is, not ingested into the managed, replicated, bit-checked archive, but rather held on (relatively) short-term processing storage, until problems with the content could be resolved with publishers.
This was a problem with respect to the quality of storage for that content in the interim, of course. And this meant an even bigger, and, worse, expensive problem: each one of those problematic batches required intervention by Portico staff. Over time, the percentages looked like this:
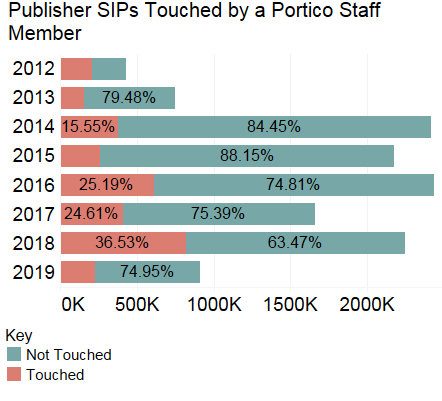
With SIPs numbering more 100 million, comprised of 1.7 billion files, the absolute number of problematic submissions was both a growing and a troubling drain on resources.
So, how to prevent geometric content growth from turning into geometric cost growth? That’s what we undertook to explore in our “Straight-to-Ingest (S2I)” project.
Rather than retain batches with content that we considered to be imperfect in the ConPrep system, we would ingest batches with both problematic and unproblematic content into the archive. All content going into the archive would now be assigned a grade, which would be included in the preservation metadata.

An “A” grade means all the components of an archival unit (a journal article, for example), were valid and as expected. A “B” grade indicates some relatively minor error or omission that would not prevent access to the object itself -- for example, a missing figure graphic image file for which we have a PDF file that provides the full content of the article. An F grade would mean there is no viable rendition of the artifact available in the SIP.
In addition to the grading system, we added a robust error tracking system as part of our new analytics services, to help us respond rapidly to changes in the ratio of problematic to pristine content provided by a publisher. It also enables us to prioritize errors, and our response to them, based on their extent and urgency. We have added new automated reporting capabilities and we integrated publisher responses into our analytics and error information. This means, for example, that we can record and track both publisher-provided repairs to previously ingested content, as well as notation of the publisher response informing us that they are not able to repair the content.
Perhaps most important, all that previously “invisible” content is in managed, replicated preservation storage, and (along with information about any defects) is now visible on our audit and access sites to publishers, libraries, and the scholars they serve.
Early outcomes from the project are encouraging. A significant amount of perfectly valid content that would have languished in ConPrep is now being ingested into the archive, along with less-than-perfect content that is annotated to indicate what precisely is problematic about it.
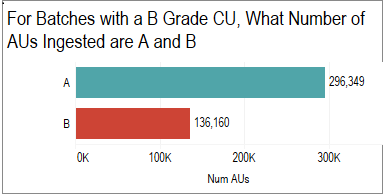
And, we are seeing fewer batches stalled in ConPrep, requiring intervention.
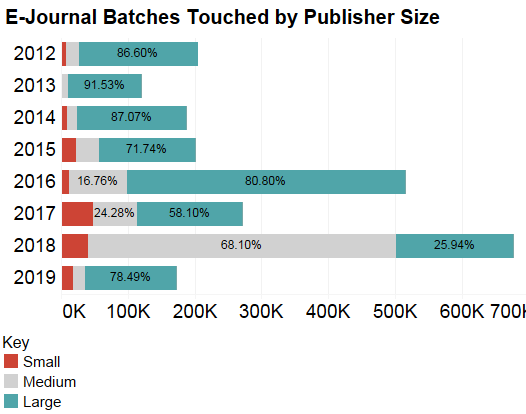
In sum, we see the implementation of “straight-to-ingest” as providing these benefits:
- Move all content into secure, managed, long-term preservation storage
- Scale our manual production processes without increasing staff
- Minimize manual interventions to correct defective content
- Flexibly and rapidly address major, urgent content defects
- Bring information about all content into our holdings metadata
- Provide greater transparency about the current state of content
If you’d like to learn more about the project, please see our iPRES2019 paper.
Comments
Did not realize the iPRES OSF site was not public yet -- this link should work:
https://ipres2019.org/static/pdf/iPres2019_paper_121.pdf
Let me know if it doesn't.