
Tom J. Smyth (Manager, Digital Preservation) and Maxime Champagne (Digital Preservation Repository Supervisor), Library and Archives Canada
Early this year, it became a priority for LAC’s Digital Preservation unit to reconsider the context of (and affect a major update to) our policy statement on the file formats we accept for transfer of digital library and archival documentary heritage.
In the course of examining the existing documents, a few issues arose for discussion among the preservation divisional staff:
-
We didn’t have a good handle on what our file format migration capacity was, and we didn’t have a means of beginning to quantify it (technology options and people);
-
We had no evidence-based means to demonstrate to our institutional clients (whom are responsible for making digital acquisition decisions), that a sliding scale of preservation challenge and cost (financial, FTE and capacity), is inherent to proprietary, obsolete, or bad quality data (put another way, how do you demonstrate to a client that one file is more problematic than any other without a framework that defines and clearly illustrates the differences/risks/costs?);
-
We could not engage in meaningful digital preservation planning without tremendous effort.
Some systematic means of addressing these issues was needed, which also had to be deployable in real-time to e.g., facilitate acquisition and preservation conversations and decisions.
Updating the LAC LDFR and Defining Categories of Digital File Format
Our policy statement on recommended digital file formats for transfer of documentary heritage to LAC[1] had not been updated for some time (2014!) and needed to be modernized and refreshed. We began by converting our document-based list of acceptable formats into a relational object as a means of quick assessment and to facilitate keeping it easily updatable and evergreen. We then re-designed the migration workflow with changes to reflect our desired, future-target state: 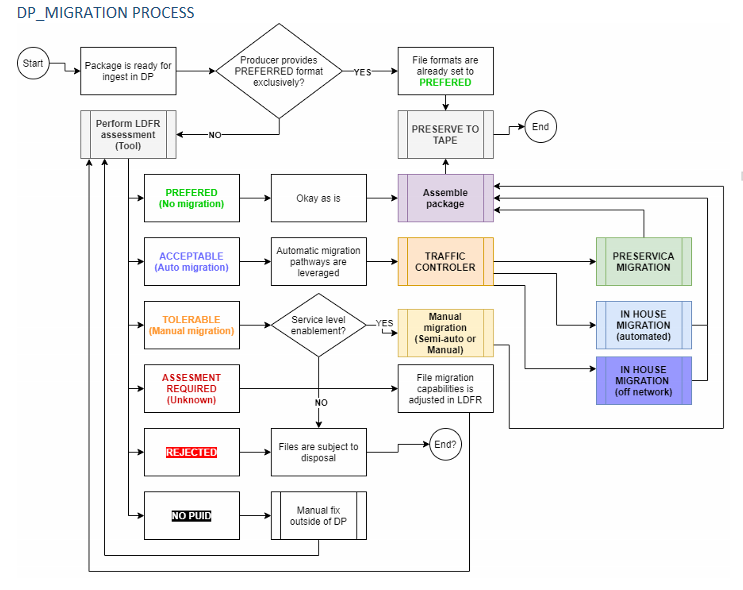
We needed to consider what the changes tells us about our current capacity and limitations for file format migration, and then compare this perspective to what the outdated but public LDFR document was claiming. To no one’s surprise, this revealed some fossilized artifacts still lived in the old LDFR, but also that our capacity could be considerably augmented, consolidated and automated if we could accommodate terabytes of needed Cloud bandwidth by operationalizing Preservica’s migration pathways and functionalities.[2]
In terms of our pre-transfer and pre-ingest operations about which we’ve blogged previously at DPC[3], DROID and its output reports are used to assess all digital library or archival acquisition data coming into LAC. We wanted to capitalize on these reports and data by sending them through the workflow and into our digital preservation master database, so the information could also be used for long term preservation planning. Thus as a next step, we added a field to the LDFR database and entered each file format’s PRONOM Unique ID (PUID) as established by The National Archives (TNA).[4]
Next we defined a series of file format categories that described how (or whether) LAC would manage each file format and version by PUID. The following themes emerged:
“A” - A preferred digital file format is one that enters the organization in an ideal format for its content type or for preservation, and which can be managed by (mostly) automated workflows from the point of entry to the organization through to creation of the Archival Information Package (AIP) in the LAC digital preservation environment.
“B” - An accepted digital file format is one that is not ideal for its content type or preservation and therefore must be immediately migrated to a new format for the purposes of producing the AIP, but which can be managed via an existing and automated workflow.
“C” – Assessment required typically means the format must be 1. manually migrated by a staff member (and so constitutes data that must be managed at a higher level of DP treatment), rather than being covered by an automated migration pathway. Alternatively, it could flag that 2. the file has a PUID, but was not flagged as either preferred or accepted as of yet in our LDFR, possibly because this is the first time we’ve encountered the format in our work, or 3. because it was flagged in the LDFR database for re-evaluation.[5]
“D” - Rejected means the file format is one we have flagged as problematic or one that is beyond our current capacity to easily migrate, especially at scale.
“E” - Cannot assess means DROID failed to identity the file format in question due either to the inability to read the file header or due to the absence of a file name suffix, which prompts additional investigation.
LDFR Tool Development as an Extension of DROID
Having identified where each PUID sits within these established LDFR file format categories, it was now possible to consider the rapid development of a scripted tool that would read a DROID report as input, and compare that data with our LDFR database by PUID to output a new type of report in real time: 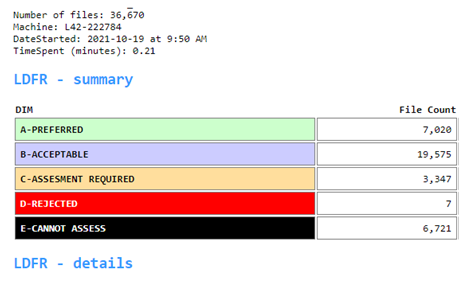
Messy dataset!
The result is a colour-coded HTML report that can be expanded to show all the formats, while grouping the DROID payload data into the LDFR’s categories – which shows the responsible acquisition area and the digital preservationists how manageable or problematic the payload data is against our current-to-the-moment migration and preservation capacities. It also illustrates at a glance how the data will be managed for processing and preservation (since each category speaks to a specific workflow), which also helps define the estimated effort and duration to acquire the target data.
A fact of life for many cultural and heritage organizations is accepting important data from a prominent donor in whatever state it happens to be in.™ This LDFR tool now assists us by providing objective evidence with which to advise internal clients on the digital curation tenability and sustainability of any given digital acquisition for LAC as an organization –given finite resources. Eventually, this will help inform PAIMAS agreements where necessary. Also, where internal clients want to acquire material that is problematic for migration or preservation, the increased scope, scale, and complexity of effort (overall cost of ownership) can be better predicted, demonstrated and mapped against (in-development) levels of digital preservation treatment per our digital preservation service catalogue,[6] so that additional resources can be sought and allocated to perform the work (or result in re-prioritization of the effort to a more important acquisition job). Given the framework that is now in place, we can also begin building the data necessary to articulate our bandwidth requirements for the use of Preservica’s pathways for performing migration work in the Cloud.
To ensure that the consulted document is always current, a script was developed to export and format the evergreen LDFR database into an eye-readable document, for on-demand distribution to internal and external clients as the need arises.
As this is being written, we are in the process of rolling the LDFR tool out to the PAIMAS area of our Digital Preservation division at LAC, so that these reports can be generated before acquisition decisions need to be made -- ideally at the pre-transfer stage of the lifecycle. Rolling the LDFR document out to clients and other departments in the Government of Canada before the pre-transfer/pre-ingest stage and providing advice and guidance on what formats to use in creating new content has already begun. While legacy data is legacy data and this won’t always work, hopefully it will mitigate some of the financial costs of data migration. Applying the thinking as far upstream as possible is our goal, to enable early warning and analysis, leading to better preservation and capacity management.
The Digital Preservation area will also begin including the DROID and LDFR tool reports in the AIP payloads, thereby transferring the file format analysis, capacity context, and file format migration decisions forward into our Digital Preservation (DP archive) master database -- as additional context and provenance information, that may elucidate preservation decisions made now for the benefit of our successors in the future. Placing this information within the AIPs and transferring it to our DP master database for all new data or migrations also addresses the need and begins the process of building much more useful data for the purposes of (LTO magnetic tape) collections management and future digital preservation risk management and planning.
Going forward, we’ll also generate operational statistics that show where our digital preservation efforts and capacity are being directed, within a dashboard reporting tool that will be shared across the organization. Overall, we think this LDFR work and tool will make great steps toward the future, which might even be worth discussing as part of #WDPDP2021!
Our LDFR tool is developed in PowerShell. We feel it and this means of capacity management could be easily repurposed, and would only need the formats and capacity assessments conducted. The tool is in turn driven by the content and categorization present in the source LDFR database, which then rolls out to all clients without the need for updating the tool. The tool could be available on GitHub on-demand if you’ve read this far!
Cheers,
Tom J. Smyth and Maxime Champagne
[1] Referred to internally as our “Local Digital Format Registry” or LDFR.
[2] Preservica is the core module of a suite of systems utilized at LAC for the management of digital library and archival documentary heritage, which we refer to as whole as the Digital Asset Management System (DAMS).
[3] Heather Tompkins, Preserving the bits : Library and Archives Canada’s Pre-Ingest workflow . Last updated on 4 November 2020.
[4] https://www.nationalarchives.gov.uk/information-management/manage-information/digital-records-transfer/file-formats-transfer/
[5] In general, for C. #1 and in a PAIMAS context, this might trigger an assessment of documentary heritage value vs effort required to acquire the target content (or might be something we should negotiate with a potential donor and/or the internal client, especially if the effort level if high).
[6] Inspired by NDSA’s Levels of Digital Preservation https://ndsa.org/publications/levels-of-digital-preservation/