Roxana Maurer is the Digital Preservation Co-ordinator at the National Library of Luxembourg (BnL).
At the National Library of Luxembourg (BnL), we are in the midst of ingesting our Web archive into our Digital Preservation system. Or I should better say trying to ingest… Web archives are different in so many ways from more “traditional” digital content like PDFs or TIFFs, that they come with many challenges and that includes the transfer to a digital preservation system. I would like to present here some of the challenges encountered at the BnL these past weeks, as an introduction to the special meeting of the DPC Web Archiving & Preservation Working Group on the 10th of June 2020.
Before diving into the more technical details of ingesting the web archive into the digital preservation system, here is a very short introduction about BnL’s web archiving programme. The Luxembourg Web Archive is operated by the National Library under the Luxembourg legal deposit and it includes broad crawls (the entirety of “.lu” web addresses), thematic and event crawls. Access for users is restricted to the Reading room of the National Library. For more in-depth information about the web harvesting programme, how it is done, collection information and much more, please visit webarchive.lu, an information platform created and maintained by my colleague Ben Els, Digital Curator for BnL’s Web Archive.
With about 65TB of websites in our Web Archive and more on the way (especially with the extra crawls done because of the Covid-19 pandemic), it was time to consider ingesting these files into the digital preservation system in order to at least ensure bit preservation of all this important data. We decided to start with our very first broad crawl from 2016 to see how everything works and get an estimate of the time and effort needed. And now we get into the more technical details…
The BnL receives compressed WARC files from our service provider, so my very first question was whether we should ingest the compressed or uncompressed files into our digital preservation system. After several discussions with my colleagues at the BnL, I decided to also ask Web Archiving and Digital Preservation colleagues on Twitter:
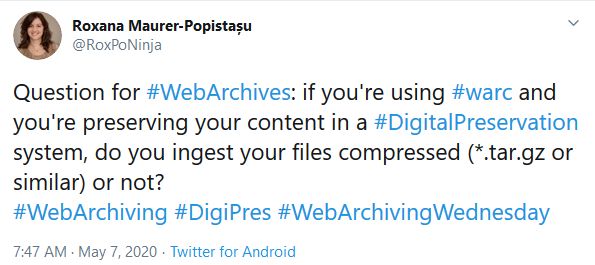
What I didn’t know at the point of writing that tweet is that we actually receive *.warc.gz files and not *.tar.gz, as I wrongly thought. My colleague Yves Maurer, technical manager for the Web Archive, pointed out to me that “warc.gz” is a recommendation in the WARC File Format (ISO 28500) specification: “The WARC format defines no internal compression. Whether and how WARC files should be compressed is an external decision. However, experience with the precursor ARC format at the Internet Archive has demonstrated that applying simple standard compression can result in significant storage savings, while preserving random access to individual records. For this purpose, the GZIP format with customary "deflate" compression is recommended, as defined in [RFC 1950], [RFC 1951], and [RFC 1952].”
My tweet sparked a discussion with arguments on both sides of the aisle, with even a recommendation for a greener Digital Preservation (It's Not Easy Being Green(e): Digital Preservation in the Age of Climate Change):
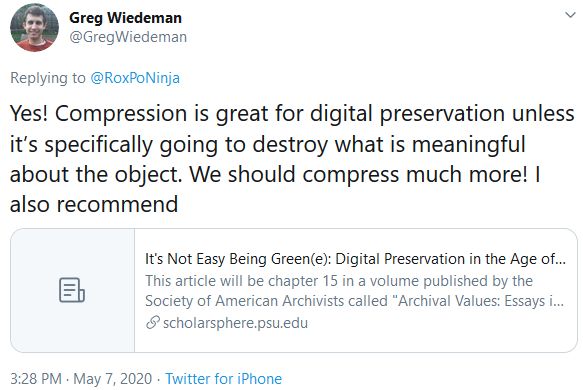
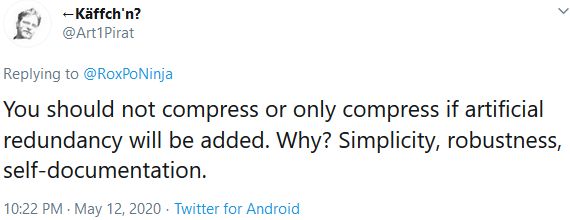

Several DPC members thought this warranted a special meeting of the DPC Web Archiving & Preservation Working Group, which will take place on the 10th of June 2020 and will have the compression of web archives as the first item on the agenda.
Before concluding this post, I would like to give you a few more pieces of information about where we are now at the BnL in terms of ingesting WARCs from our Web Archive. We decided to go with ingesting compressed WARC files (warc.gz, that is) and here are some things you might want to consider, if you’re going the same way.
The first try was with 10 ingest workflows, each containing 100 warc.gz files with a size of approximately 100GB per SIP. I thought that was a reasonable try, having ingested much bigger SIPs into our preservation system, but I couldn’t have been more wrong. This was clearly visible when all my workflows were terminated some 36 hours later, because they ran out of disk space on the Job Queue server. First lesson learnt: compressed files need a lot more temporary space to do the un-compression and the characterization of the individual documents within the WARC container.
The second try was with one single workflow, but using one of the initial SIPs containing 100 WARC files of about 100GB in total. About 48 hours after the start this workflow terminated as well, having succeeded at charactering all the documents, but stopping at the “Store Metadata” step, when the technical information should have been saved into the database. To try to debug this we did some calculations and reached the conclusion that each warc.gz contains an average of 21.000 documents, which means that we were trying to characterize and save the metadata for about 2.1 million documents in one go! No wonder the system stopped working after some time…
After discussing the issue with colleagues from other institutions, we are now at the stage where we are reducing to the maximum the number of WARCs per submission package: 1 SIP contains 1 compressed WARC. I’m happy to report that the first ingest in the Test environment was successful. Now we have to start the optimization process and see how many workflows we can run in parallel, before the performance of the preservation system is impacted negatively again.
A tangent discussion we are having now is whether characterization of documents within the WARCs is really necessary at ingest time. Isn’t it more important to go with a minimal effort ingest approach: finish ingesting the web archive to ensure the bit preservation of the files (which might take several months anyway) and do the file characterization at a later point? Within or even outside of the digital preservation system.
Another interesting question arising from the point above: should this technical metadata be saved in the database of the digital preservation system, in the AIP itself or even in a separate system? One interesting Twitter discussion about this topic was started by a statement made by Micky Lindlar and that initially had nothing to do with WARCs and technical characterization metadata:
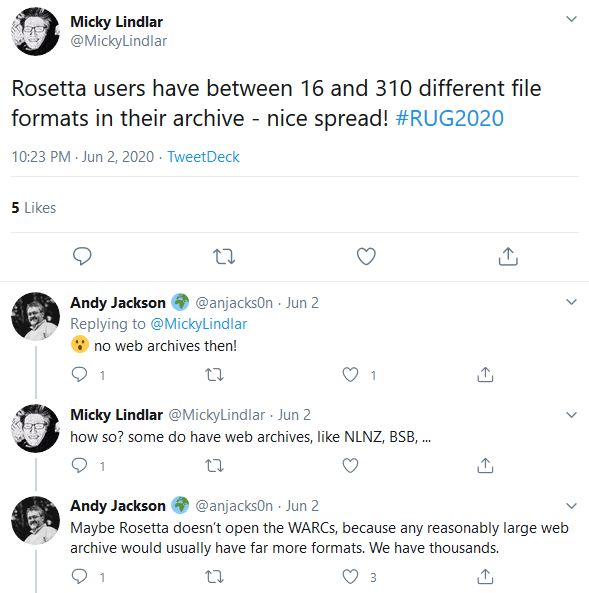
Go on Twitter and follow the whole thread if you’re interested (despite the initial tweet, it is product agnostic). It goes on to discuss how the British Library is saving the characterization data from the web archive, but also to debate the question “If you don’t store the format info in the archival package, how do you assign risk for later migration?”
I’m going to finish my post here and leave you with Micky’s conclusion, which makes for a very good point for today’s meeting as well: