















































































































































Definitions
Computational access is often linked with terms such as text mining, machine learning and artificial intelligence, so much so that there is understandable confusion around what each of these concepts entails and where the areas of overlap occur. This section provides clear definitions of key terms and the relationships between them.
Computational Access
The term computational access relates to the ability to enable users to access collections within a digital preservation repository (in a machine-readable manner, e.g., via download or API) in order to analyze, interrogate, or extract new meaning from that material (through, e.g., data or text mining, machine learning) as a means of investigating a particular research question.
This term is first found in the literature in a report by HathiTrust and is closely linked to ‘Collections as Data’ which similarly urges organizations to make their collections available as data, therefore making it possible for users to compute over the material. The term is closely linked to a number of definitions, highlighted in bold above; these and other related terms are discussed below in alphabetical order.
Algorithms
An algorithm is a set of coded instructions normally followed to solve specific problems. A real-world example would be baking a cake; other examples are the process of doing laundry, or the method used to solve a logistic problem.
Artificial Intelligence (AI)
Artificial Intelligence (AI) has been defined by the UK Parliament as:
‘Technologies with the ability to perform tasks that would otherwise require human intelligence, such as visual perception, speech recognition, and language translation.’ They also add that ‘AI systems today usually have the capacity to learn or adapt to new experiences or stimuli.’ AI in the UK: ready, willing and able?
Artificial Intelligence typically takes one specific task, which would normally be done by a human, and provides a method of reliably automating it. An example of this is classifying traffic signs, or recognizing the handwriting of a particular scribe. It especially comes in handy when working with large amounts of material which are extremely time consuming to process manually. Recent developments relating to AI and archival thinking and practice are discussed in the article Archives and AI: An Overview of Current Debates and Future Perspectives.
AI can be split into Broad AI and Narrow AI, and these terms are further defined below.
Broad AI represents a system that is sophisticated and adaptive, able to perform any cognitive task based on its sensory perceptions, previous experience, and learned skills. Currently this type of AI is not achievable due to technical limitations. Read more about steps towards a broad AI.
Narrow AI is task focused. This type of AI is very good at doing one single task, for example, classifying documents into different topics. It is also referred to as Weak AI.
Sometimes Narrow AI becomes so good at a specific task that it can give the impression that it is able to think for itself, so falling under the Broad AI marker. An example of this would be the quick improvement of Voice Assistants, such as Alexa. However, current technology is only able to support Narrow AI.
More information on the differences between these two terms can be found here: Distinguishing between Narrow AI, General AI and Super AI.
Algorithms are a large component of AI, but differ slightly, as AI takes the use of these a step further. AI is basically a set of algorithms that can modify and create new algorithms in response to learned inputs and data, as opposed to relying solely on the inputs it was designed to recognize as triggers.
Computer Vision
Computer vision is a sub domain of AI that focuses on deriving meaningful information from digital images. In an archives context, computer vision could be used to generate metadata for a set of uncatalogued digital images to enable more effective processing, or search and retrieval. A good example of this can be found here: Libraries Use Computer Vision to Explore Photo Archives. As digital images can be of a complicated nature, machine learning is the methodology typically used to carry out this task. You can find out more about computer vision here: What is computer vision?
Data Mining
Data mining is the discipline of finding patterns, correlations, and anomalies in data. A broad range of techniques can be used in data mining, including AI. The data mining workflow can be roughly split into data gathering, data preparation, training, and data analysis. AI is most commonly used during the training stage; this is when the algorithm is trained in a specific task. However, as this discipline mainly focuses on using large amounts of data, AI and algorithms can also be used to aid other steps of the workflow. For example, an algorithm could be written to gather certain information from the web. Find out more about data mining here: Data Mining: What it is & why it matters
Machine Learning
Like computer vision and Natural Language Processing (NLP), machine learning is a sub domain of AI. It differs slightly from computer vision and NLP, as it focuses more on the infrastructure and models than on the techniques and material that are being inputted. Machine learning takes AI to the next level; not only are the algorithms adaptable, but they are also able to perform a task without being explicitly programmed to do so. Find out more about machine learning here: Machine learning. An example of using machine learning on archival collections can be seen on the Archives Hub blog: Machine Learning with Archive Collections.
When talking about AI and machine learning, the terms supervised and unsupervised are sometimes used. These refer to the different approaches that can be taken when applying machine learning. Supervised learning is where a labelled dataset will be used for the algorithm to learn from. A labelled dataset contains items that are tagged (mostly by humans) with an informative label; one example of this is a labelled dataset of images with names of the people who appear in them attached. Unsupervised learning uses a dataset that has not been labelled. This is the biggest difference between these two approaches, but a more nuanced explanation can be found here: Supervised vs. Unsupervised Learning: What’s the Difference?
A term that is also closely linked to machine learning is deep learning. This is a more complex form of machine learning where deep neural networks are used to resemble the complex structure of the human brain. Read more about the differences between deep learning and machine learning here: Deep Learning vs. Machine Learning – What’s The Difference?
Natural Language Processing (NLP)
NLP, just like computer vision and machine learning, is another sub domain of AI. This sub domain focuses on the ability of a computer program to understand human language as it is spoken and written. You can read more about NLP here: Natural Language Processing (NLP). Most of the time, due to the complexity of human language, machine learning will be used alongside NLP to produce better results. An example of this is text classification, where due to the ambiguous and unstructured nature of human language, this approach has only been able to evolve since the use of machine learning.
Text Mining
Text mining is very similar to data mining, the biggest difference being that instead of collecting data in general, text mining focuses solely on collecting text. Therefore, while text mining is data mining, data mining is not necessarily text mining. Text mining typically results in a large quantity of unstructured text which is difficult to analyze, so more advanced methods such as machine learning are often used in association with it to help make sense of the resulting dataset. Read more about text mining and its relationship to machine learning and NLP here: What is Text Mining, Text Analytics and Natural Language Processing?
As is apparent from the definitions as described above, there are close relationships between many of the terms used. The diagram below illustrates some of these areas of overlap.
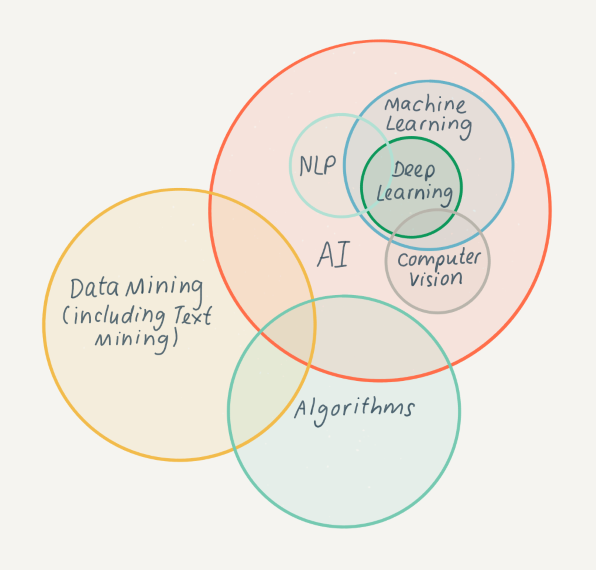
Approaches to computational access
There is more than one way to implement computational access, and the range of approaches can be confusing to those who are new to this topic. This section looks at the pros and cons of the different approaches and provides real-life examples of how they are being applied by different organizations.
Computational access can be approached in several different ways. Four approaches have been identified:
The one an organization selects will depend on its resources and priorities, the needs of its users, and any legal and ethical concerns relating to the collections or material being made available. It is also possible for organizations to apply several approaches, depending on their collections and users. The approaches described in this resource appear in order of complexity, with simpler solutions first, followed by those that require greater commitment of time and resources.
This recording from Leontien Talboom at our launch event in July 2022 provides a helpful introduction to computational access and a clear overview of the four different approaches.
Leontien Talboom, University College London - An introduction to computational access
Ethics of computational access
No guide to computational access would be complete without discussion of some of the ethical issues which should be considered when applying these techniques. This section provides a summary of some of the key considerations and signposts further sources of information.
The digital preservation community has inherited and further developed a sophisticated understanding of the ethics surrounding the provision of access to heritage collections, an understanding which is having to become even more sophisticated in respect of the provision of digital access. Some of the challenges around the ethics of access, with a particular focus on approaches and tools that have been applied at the Australian Institute of Aboriginal and Torres Strait Islander Studies (AIATSIS) are summarized in Exploring ethical considerations for providing access to digital heritage collections.
The provision of computational access will require a similar evolution in understanding for several reasons. Firstly, because computational access, as defined in this guidance, generally involves the use of algorithms or other computational methods, some of which are not in themselves commonly understood or easily explainable. This leads to issues with maintaining transparency and accountability with respect to, and hence trust in, their use and the conclusions and outcomes that arise from that. Arguably, we should for this reason be circumspect in adopting such techniques for our own (digital preservation) purposes.
Secondly, a common factor in the use of algorithms and other computational methods is the desire to be able to work at scale, processing larger amounts of data at one time than was previously possible using more traditional methods, and being able to combine disparate datasets to create a clearer picture. The bigger the scale, the bigger the potential for harm and unexpected outcomes, particularly when the data being worked on are about people. This potential for harm is heightened still further by the fact that the regulatory environment for the use of algorithms and computational methods (in all contexts, not just for the provision of computational access to digital heritage collections) is itself in an unsophisticated state of development, with discussion ongoing and the absence of any form of widely held consensus on the topic. There is a good discussion of some of these questions here: Algorithmic accountability for the public sector.
In large part then, there is an element of ‘watch this space’. However, a first step could be to enhance our documentation of any ‘sets’ of material or data to which computational access is anticipated or offered. Within the AI and data science communities increased attention is being paid to dataset documentation; see, for example, Datasheets for Datasets – Microsoft Research or the work by Eun Seo Jo and Timnit Gebru from the machine learning community. While some of the questions asked as prompts to documentation may seem odd to those used to describing digital assets for non-computational use, this highlights the information needed in order to ensure that they can use it safely. Similarly, projects such as The Data Nutrition Project and Data Hazards flag up some of the already known dangers for those wishing to analyze data using computational means and a blog from the Archives Hub describes some of the challenges of understanding the effectiveness of, and bias within the tools.
When providing access to collections, improving the documentation we offer to support users to use it more safely would seem to be the least we, as practitioners, can do. It would provide users with a context for the material and help them to make an informed and ethically responsible choice as to how to use it. Although what users ultimately do with this material is their responsibility, there is perhaps still a debate to be had about whether, in light of the increased potential for harm and the nascent regulatory environment, we feel it is our responsibility to police the uses to which our collections are put even more stringently than in the past. A good way to get started is to provide terms of use, discussed in the approaches section of this guide. Should we prohibit certain types of use? And if so, how do we design systems and procedures to prevent these?
Benefits and drawbacks
Understanding the benefits of using computational access is key to helping practitioners decide whether it is something they should explore. Awareness of the hurdles that might be encountered along the way is equally important in aiding those decisions and in helping understand the potential pitfalls once implementation begins. This section summarizes some of the key points to consider.
Benefits
Computational access opens up potential benefits both for digital preservation practitioners and for users of their digital collections. Some of the key benefits are listed below:
-
Handling bulk requests will no longer need manual intervention by staff (though note that staff time may well be spent supporting users in other ways).
-
It is empowering for the digital preservation community, as the importance of documentation and contextualization can be emphasized. See Nothing About Us Without Us for a discussion on this theme.
-
Computational access techniques enable and encourage the possibility of collaborative working with other disciplines, such as digital humanities/cultural analytics/computational social science, especially when considering access through an API, and this may bring wider professional benefits.
-
It allows digital preservation practitioners to more effectively meet the needs of users, empowering them to explore collections in novel and innovative ways and opening up possibilities for new types of research. Platforms such as GLAM Workbench are helpful in demonstrating what is possible.
-
It provides opportunities for developing new digital skills, both for digital preservation practitioners and for users.
Drawbacks
Alongside the benefits described above, there are several potential drawbacks to using computational access techniques. These are listed below:
-
Unintended bias or privacy concerns in the collections may not be revealed until the material is made available at scale.
-
Loss of control. It can be unclear who is using the material, therefore there could be unanticipated and unpredicted outcomes. This could be partly controlled with the implementation of terms of use or a policy on the use of derivative datasets, such as that published by HathiTrust.
-
Providing computational access is a long-term commitment with associated costs. It needs to be planned and resourced correctly for it to be successful.
-
Users may become reliant on computational access services that are being trialled by an organization. Managing user expectations when prototyping new types of access is important to factor in.
-
Data comes with an erroneous aura of objectivity, which can lead to the idea that it is unbiased; this is far from the truth for a lot of organizations. For more detail see Lessons from Archives: Strategies for Collecting Sociocultural Data in Machine Learning.
Constraints
There are also several constraints or barriers that are stopping the community moving forward with computational access. Some ideas to help overcome these can be found in the ‘Practical Steps’ section of this guide.
-
Lack of technical skills and resources within an organization to implement this approach.
-
Sustainability of the implemented architecture. Digital infrastructures and tools need to be appropriately resourced in order to ensure they are maintained over time.
-
Depending on the type of collection you want to enable access to, licensing and other copyright restrictions could make computational access difficult. An example of this is UK copyright laws around data and text mining.
-
Lack of use cases or demand for computational access can make it difficult to know what approach to implement to meet user requirements.
-
The available tools that can enable and help with this type of access are not necessarily tailored towards the requirements of digital preservation practitioners, which can make it time consuming to implement and maintain.
Practical steps for moving forward with computational access
Taking the first steps to implement or work with a new technique or technology can be a challenge, particularly when you do not know how, or even where, to start. This section offers practical tips to help digital preservation practitioners move forward, as well as case studies demonstrating how others have tackled the challenge.
Circumstances will vary widely in terms of the resources and technical skills available to an organization as well as in the type of material they are hoping to provide access to. However, the following ideas should provide a useful starting point for further exploration, whatever your circumstances. These '23 things' focus on actions aimed at both individual practitioners and at organizations, though of course there will be some overlap and you are encouraged to consider all points.
Steps for an individual practitioner
-
Do something! It is easy to be overwhelmed by the possibilities available, but the best way to learn is to experiment. For example, if you can safely do so, consider making a small dataset available and seeing how people use it.
-
There are great free resources available to learn more about computational techniques – use these to build your capacity. Good places to start are the Programming Historian or Library Carpentry. There are links to more resources at the end of this guide.
-
Talk to people you do not normally talk to. A computational access project will benefit from a multi-disciplinary approach, and the more people with different perspectives you can talk to about it, the better. This could include people within your organization or in the wider community.
-
Scope out your project meaningfully. While it might be tempting to just say ‘I want all the data’, that would not work in an 'analogue' project and will not work in a digital one either.
-
Check the licences and terms of access that apply to the material you are working on, collate these in a document so you know, and can share, what users can legally do with your content.
-
Look for existing datasets you can use to enrich the data you will be working with. For example, you might work in an organization that has catalogue entries you could incorporate into your project as metadata.
-
Familiarize yourself with the various approaches to computational access discussed in this guide. They might all be useful to different types of user, but there are implications for the skills and resources you need for your project.
-
Computational approaches and their outputs can lend work an aura of ‘objectivity’ that should be treated with caution. Keep in mind that your outputs might look more authoritative than perhaps they should, so think about how you can explain and qualify them. Make your assumptions and processes transparent to the user if you can.
Steps for an organization
-
Consider how computational access may align with, or support, organizational strategy. Being able to demonstrate a link may help you to make the case to explore new methods of access and gain the support of colleagues.
-
Apply an active outreach approach. Speak to your users, set up user groups, conduct interviews. Try to help them articulate what they want (or might want if they knew about it) from computational access.
-
Consider your own colleagues as a user community for computational access. While you might aspire to attract a new group of external users, computational access can also be of great benefit internally, by, for example, increasing your own understanding of your collections.
-
A good way to generate ideas is to create a single dataset in a familiar format such as CSV, and host an internal hackathon, giving staff time to play with the dataset and see what they come up with.
-
Think carefully about where the expertise to guide service provision for computational access lies in your organization, and how you can engage the right people. Bear in mind that expertise and responsibility might not always go together.
-
Consider sustainability from the start. Remember that users may come to depend on the services you are planning to deliver, and you have a responsibility to think about how you will sustain them. Consider the resource commitment you will need and the environmental impact of your project. Though not specifically focusing on computational access, the article Towards Environmentally Sustainable Digital Preservation discusses the need for a paradigm shift in archival practice and touches on the environmental impact of mass digitization and instant access to digital content.
-
Make documentation an integral part of your project from the very beginning. Part of the appeal of computational access is that others can build on your work in new and unexpected ways. A well-documented service, ideally with worked examples, will help facilitate this.
-
Consider funding or empowering other users to approach your collections in new computational ways. For example, you could run a content hacking competition or workshop for postgraduate students and/or community practitioners to imagine potential uses of your content.
-
Find a public domain or CC0 ‘No Rights Reserved’ collection, dataset or set of metadata and publicly release it. This can serve as a trial run to work through your processes, and as a way of engaging with users and working out what to do next.
-
Search for existing standards you can use. Do not reinvent the wheel if other organizations have done already done similar work. For example, if you adopt similar data output forms to other organizations, it will make it easier for users who are already familiar with the standard.
-
Ask lots of awkward questions during the procurement of any system. This might feel uncomfortable but will save problems in the long run. Engage expert colleagues to help you with this if needed.
-
When testing your system, and when you are in production, be sure to question your results – are you able to identify and describe bias in the results? Do not take the computer's answer as right! The following article is an interesting reflection on selection and technological bias of the Living with Machines project: Living with Machines: Exploring bias in the British Newspaper Archive.
-
It is important that users can contact you with questions or to request further data from your collection, so provide a primary contact or a contact form as part of your project.
-
Make sure you have a defined plan to transition discussions of ethics to concrete actions in systems, processes, and collaborations.
-
Going forward, embed computational access in your day-to-day collection accessioning and processing. New methods of access may require adjustments to organizational policy, accessioning and appraisal workflows and conversations or agreements with donors and depositors. The Reconfiguration of the Archive as Data to Be Mined is a helpful article which discusses changing practices brought about by the move to online digital records.
Further practical tips for getting started can be found in '50 things' which has been published as part of the Collections as Data framework and inspired this section of the guide. Though 50 things is not aimed specifically at digital preservation practitioners many of the tips and ideas are helpful and their key message "start simple and engage others in the process" is great advice!
Further Resources and case studies
This section highlights some useful resources recommended by our expert workshop participants.
Case studies
The case studies listed in this section provide helpful examples of how computational access techniques have been applied in practice.
-
Discovering topics and trends in the UK Government Web Archive by the Data Study Group at the Alan Turing Institute – ‘A detailed case study demonstrating a series of experiments to unlock the UK Government Web Archive for research and experimentation by approaching it as a dataset.’ Jenny Mitcham, Digital Preservation Coalition
-
Providing computational access to the Polytechnic Magazine (1879 to 1960) by Jacob Bickford – ‘A practical and accessible case study describing a project at the University of Westminster which used NLP to provide computational access to a collection of digitized material. It includes links to useful resources that helped with getting started, and the code developed is also shared so that others can make use of it.’ Jenny Mitcham, Digital Preservation Coalition
-
Datathon slides highlighting possibilities with the material by the Archives Unleashed Project – ‘A collection of slides from datathons run as part of the Archives Unleashed project, these highlight a number of computational methods that could be applied.’ Leontien Talboom, University College London
-
Using AI for digital selection in government by The National Archives (UK) – ‘Outputs from an experiment which tested and evaluated a series of tools to undertake automated classification of a dataset to predict retention labels.’ Jenny Bunn, The National Archives (UK)
-
Reflecting On a Year of Selected Datasets by Predo Gonzalez-Fernandez – ‘A useful write up of how datasets have been made available at the Library of Congress.’ Jacob Bickford, The National Archives (UK)
-
Exploring National Library of Scotland datasets with Jupyter Notebooks by Sarah Ames and Lucy Havens – ‘An interesting example using Jupyter Notebooks to explore National Library of Scotland collections in a different way.’ Leontien Talboom, University College London
-
Web Data Research blogs by the Internet Archive – ‘Multiple examples of types of use and various tools, platforms, and partnerships.’ Jefferson Bailey, Internet Archive
-
Machine Learning with Archive Collections by Jane Stevenson – ‘This blog post shows the possibilities and potential of machine learning when applying it to archival collections.’ Leontien Talboom, University College London
The case studies below were shared as part of a series of events to promote the launch of this guide and represent a range of different approaches to computational access.
Jacob Bickford, The National Archives UK - ‘DIY’ Computational Access: the Polytechnic Magazine (1879 to 1960)
Sarah Ames, National Library of Scotland - Collections as data at the National Library of Scotland: access, engagement, outcomes
Ian Milligan, University of Waterloo - Providing Computational Access to Web Archives: The Archives Unleashed Project
Ryan Dubnicek and Glen Layne-Worthey, HathiTrust Research Center, University of Illinois Urbana-Champaign - How to Read Millions of Books: The HathiTrust Digital Library and Research Center
Jefferson Bailey, Internet Archive - Tales from the Trenches: Building Petabyte-scale Computational Research Services
Tim Sherratt, University of Canberra - Living archaeologies of online collections
Examples of approaches and infrastructures
The list below provides some helpful examples for you to explore, showing how different organizations have opened up their collections for computational access using a variety of techniques:
-
SHINE – ‘This is a prototype search engine for UK Web Archive with trend analysis. It is a good example of what is possible but is also very user friendly – a great way of introducing people to looking at a digital resource in a different way.’ Jacob Bickford, The National Archives (UK)
-
GLAM Workbench – ‘A set of Jupyter notebooks, demonstrating different computational techniques. This is great for its broad range of subject matter and exposing the underlying code.’ Jacob Bickford, The National Archives (UK)
-
SolrWayback – ‘Search tools for web archives, again a great demonstration of what is possible.’ Jacob Bickford, The National Archives (UK)
-
DigHumLab – ‘A digital ecosystem that highlights a number of collections open for computational access, also includes some inspirational examples of how researchers have used these collections.’ Leontien Talboom, University College London
-
Data Foundry – ‘This is a good example of access to National Library of Scotland data collections.’ Jane Winters, University of London
-
Web Archive Datasets – ‘Datasets made available by the Library of Congress Labs including Jupyter notebooks on working with the meme collection.’ Jacob Bickford, The National Archives (UK)
-
The Cybernetics Thought Collective – ‘A digitization project that also provides a web portal and analysis engine and highlights the potential of computational methods for this type of material.’ Leontien Talboom, University College London
-
BigLAM (Libraries, Archives and Museums) - ‘This collaboration showcases how there is an interest in GLAM material in the form of data. The provided datasets also highlight what attributes may be of importance to people wanting to use this material for different computational methods.’ Leontien Talboom, University College London
Further reading
This guide has provided an introduction to computational access for beginners but of course there is no shortage of further reading on the topic. The following articles, papers and blogs have been recommended by the contributors to this guide and can be used to explore the topic in more depth:
-
The Web as History by Niels Brügger and Ralph Schroeder – ‘Highlights a number of examples that could be used to explore web archives, also discusses the broader constraints and benefits of using this type of material.’ Leontien Talboom, University College London
-
Lessons from Archives: Strategies for Collecting Sociocultural Data in Machine Learning by Eun Seo Jo and Tinnit Gebru – ‘A nice example of cross-domain exploration of what archival science/practice can offer to machine learning development – it is rare to see the relationship framed this way.’ Thomas Padilla, Center for Research Libraries
-
From archive to analysis: accessing web archives at scale through a cloud-based interface by Nick Ruest, Samantha Fritz, Ryan Deschamps al. – ‘This paper looks at how first-hand research and analysis of how researchers actually use web archives has led to the development of the Archives Unleashed Cloud – an online interface for working with web archives at scale.’ Ian Milligan, University of Waterloo
-
Responsible Operations: Data Science, Machine Learning, and AI in Libraries by Thomas Padilla – ‘This report discusses the technical, organizational, and social challenges that need to be addressed in order to embed data science, machine learning, and artificial intelligence into libraries. The recommendations within it align closely with community aspirations toward equity and ethics.’ Jenny Mitcham, Digital Preservation Coalition
-
Ensuring Scholarly Access to Government Archives and Records by William Ingram and Sylvester Johnson - "This project provides a number of examples and recommendations when applying machine learning methods for the automatic creation of metadata. This may not be the main focus of this guide, but it does give some interesting concepts and ideas around applying these methods at scale." Leontien Talboom, University College London
How this guide was created
This guide to computational access was created collaboratively by Leontien Talboom (who received support from the Software Sustainability Institute to carry out this work, the Digital Preservation Coalition, and invited experts from across the community.
The development of this guide was informed by an initial expert workshop held online in February 2022. Invited experts were encouraged to share their thoughts on the definitions of key terms related to computational access and answer questions such as ‘what are the strengths, risks, opportunities, and barriers of computational access for digital archives?’, ‘what practical steps can practitioners take to move forward?’ and ‘what are the key resources people should access in order to find out more?’. The discussion was conducted across time zones and fuelled by cookies and cake. This workshop helped firm up the key elements that would be needed within the guide, and engagement with this group of experts continued as the resource was developed.
Also key to the evolution of this guide was an online launch event held on 6 July 2022. Lowering the Barriers to Computational Access for Digital Archivists : a launch event was intended not only to share this work with the community for the first time, but also to gather a range of helpful case studies that could be made available to further illustrate the online guide.
Attendees at the expert workshop on computational access held online in February 2022.
This guide was written by Leontien Talboom with contributions from Jacob Bickford, Jenny Bunn and Jenny Mitcham.
Our thanks go to the experts who contributed to the workshop and provided helpful comments on earlier drafts of this text:
-
Jefferson Bailey, Internet Archive
-
Jacob Bickford, The National Archives (UK)
-
Jenny Bunn, The National Archives (UK)
-
Catherine Jones, STFC
-
William Kilbride, Digital Preservation Coalition
-
Ian Milligan, University of Waterloo
-
Thomas Padilla, Center for Research Libraries
-
Alexander Roberts, University of Swansea
-
Tom J. Smyth, Library and Archives Canada
-
Jane Winters, University of London
Thanks also go to those who provided case studies on this topic at our online launch event:
-
Sarah Ames, National Library of Scotland
-
Jefferson Bailey, Internet Archive
-
Jacob Bickford, The National Archives (UK)
-
Ryan Dubnicek, HathiTrust Research Center, University of Illinois Urbana-Champaign
-
Glen Layne-Worthey, HathiTrust Research Center, University of Illinois Urbana-Champaign
-
Ian Milligan, University of Waterloo
-
Tim Sherratt, University of Canberra
 |
Elements of this work were funded by the Software Sustainability Institute. |
Approaches to computational access - Terms of use
Terms of use
All openly available data and collections should come with terms of use, as it is possible for open data to be harvested and computed over by users, even if it was not intentionally made available for computational access. The terms of use are a guide for users who wish to collect and compute over the material made available. As Krotov and Silva argue, if no terms of use are available, the scraping of sensitive or copyrighted material is left to the discretion of the user.
Here are some examples of terms of use:
-
The National Archives (UK)– this document also addresses web crawlers and bulk downloads.
-
The University of Edinburgh – information on copyright and e-resources that explicitly includes data miningand text mining.
Approaches to computational access - Bulk dataset/Downloads
Bulk dataset/Downloads
This type of computational access is where an organization makes its material available through a data download. The organization creates a dataset from its material (this may be all of its collections, or a sub section of them), processes it and then makes it possible for users to download it through an online interface or portal. These datasets are normally available in CSV (Comma Separated Values) and JSON formats, as they are ubiquitous and easy to read by both humans and computers. Read more about the CSV and JSON formats here: Our Friends CSV and JSON.
This type of access gives an organization a lot of control over the material, as it sets the parameters of what is being made available. However, this approach also requires a lot of maintenance, as the dataset will need to be updated and uploaded manually. Versioning is also something to take into consideration. For single files or downloads this may not be as problematic, but when working with large amounts of data this can be important, as results may differ from version to version, depending on what has changed and why. Even if providers cannot retain all versions of the data, users should be encouraged to correctly cite the version they have used to aid in potential reproducibility.
Once the users download the file, they will have to set up their own environment and decide what they want to do with this material. Archivists may see this as the easiest way to make data computationally accessible as it fits well with existing concepts of access and use. They are used to packaging and storing information for users to request and access and the bulk datasets approach could be seen as a very similar process.
The diagram below illustrates the simplicity of the bulk datasets approach. An organization makes a dataset available through an interface or portal. A user can then download this dataset to work with.
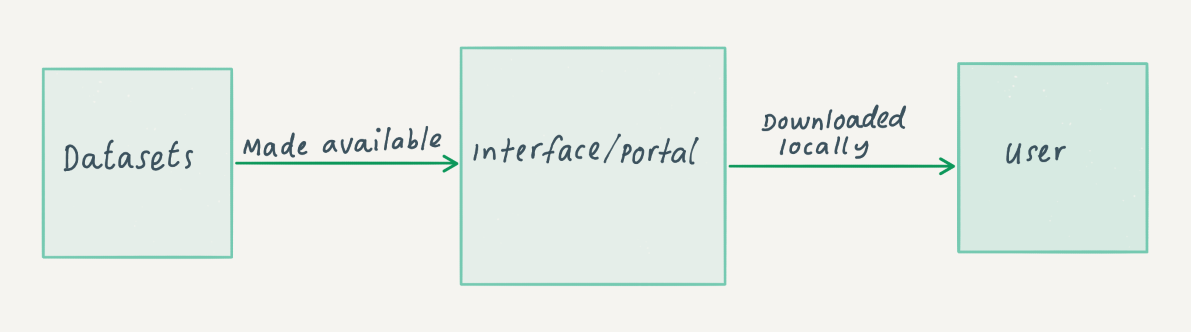
There are different ways of providing access through bulk datasets. The type of material made available as datasets may differ; some organizations will only make their metadata available in bulk, whereas others include both the data and metadata. The hosting of the datasets does not necessarily have to be done by the organization itself. It may decide to upload this material to a third-party provider. For example, large datasets from the Museum of Modern Art (MoMA) in New York are hosted through GitHub; these files are automatically updated monthly and include a time-stamp for each dataset.
A similar approach is taken by Pittsburgh’s Carnegie Museum of Art (CMoA) which also has a GitHub repository; however, this one is updated less regularly.
OPenn is another repository for datasets, specifically archival images. It is managed by a cultural heritage institution which provides access to its own material as well as material from contributing institutions.
A slightly different approach was taken by the International Institute of Social History (IISH) in the Netherlands, which uses open-source software to make its datasets accessible. A slightly modified version of Dataverse is hosted on their website.
The table below showcases a variety of ways in which the bulk dataset model has been applied at different organizations including the following:
-
Are data or metadata (or both) are made available?
-
Is data updated and versioned?
-
Which file formats are available?
-
Where is it hosted?
|
Organization/Project |
Data/Metadata |
Versioning |
Updated |
Terms of use |
Downloadable format |
Type of Data |
Hosted on |
|
Both |
Yes |
Yes |
Yes |
Available through rsync |
Unstructured book files |
Own website |
|
|
Metadata |
Yes |
Yes |
Yes |
Several formats through GitHub |
Metadata of collection |
GitHub |
|
|
Both |
Yes |
Yes |
Yes |
Depends on the dataset |
Structured research datasets |
Own website with use of Dataverse |
|
|
Both |
No |
No |
Yes |
CSV and JSON |
Object from museum |
GitHub |
|
|
Both |
No |
Yes |
Yes |
CSV, TIFF and TEI |
High Resolution archival images |
Own website |
Approaches to computational access - Application Programming Interface (API)
Application Programming Interface (API)
Another computational access approach is the use of an Application Programming Interface (API). With this, it is possible for users to send a list of instructions within certain parameters to a data store, usually a server and a database maintained by the content provider. This list of instructions is then processed, and data is returned to the user. Further information about what an API is and how they can be used can be found here: What Is an API, and How Do Developers Use Them?. The following example from The National Archives (UK) shows how it provided an API to enable users to analyze its archival catalogue data.
Using an API is a more fluid way to access data than the bulk datasets approach, as the user can be more specific on the material that they want; it also requires less bandwidth and disk space. This is a more computational approach than the bulk datasets approach, as processing the data and updating it does not have to be done manually by the content provider – the API provides direct access to the data.
The data made available by organizations may differ; some will only opt to make their metadata available, see The National Archives (UK) Discovery API, whereas other organizations, such as The Wellcome Collection, offer access to their actual data. Documentation is mainly directed at developers wanting to use these tools. However, The National Archives (UK) offers a Sandbox mode, accompanied by a blog including examples, to make it more accessible to people with fewer computational skills.
The diagram below provides a simple illustration of how the API approach works. Data is stored in the data store (normally as a database), and the user can connect to this data store via a portal or interface.
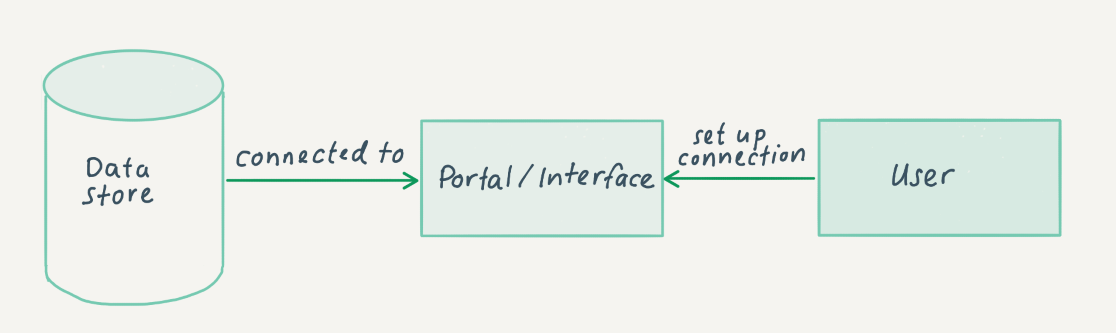
Just as with the bulk dataset approach, the API does not necessarily have to be hosted by the organization itself. Europeana offers a portal for different cultural heritage organizations and Systems Interoperability and Collaborative Development for Web Archiving (WASAPI) offers a similar idea for archived web material. APIs can have different architectural implementations. One of the most popular (also regarded as best practice) is the Representational State Transfer (REST) API. This architectural style follows a number of guidelines and has resulted in an API that is lightweight, fast and simpler by design. Find out more about REST APIs and how to use them here: Understanding And Using REST APIs.
Much of the documentation around APIs in cultural heritage institutions is unclear on their implementation; however, the WASAPI is very clear on how it has implemented and used a REST API approach and this is fully documented on GitHub. Some organizations have made a different architectural choice by including the API as an add-on to their already existing infrastructure; an example of this is the Discovery API at The National Archives (UK).
The table below lists examples of different types of APIs and describes some of the variations in their implementation, for example:
-
Does the API offer metadata or data (or both)?
-
What type of data is being offered? Is this structured or unstructured?
-
Do users have to register in order to access the API? This is a common feature of an API that may differ from other approaches (such as the bulk datasets approach). Registration to an API gives the organization an idea of who is requesting data.
|
Organization/Project |
Data/Metadata |
Type of Data |
Type of API |
Documentation |
Registration |
|
Metadata |
Structured |
As an add-on to the original infrastructure |
Yes, and includes a Sandbox mode |
The National Archives needs to be contacted and IP address should be provided |
|
|
Data |
Unstructured |
Rest API |
Yes |
N/A |
|
|
Two separate for metadata and data |
Structured |
Rest API |
Yes, but limited to developers |
No registration necessary |
|
|
Search API – for metadata and data |
Structured |
Rest API |
Yes, with multiple guides |
Registration is necessary, a new API key is needed for every implementation |
Subcategories
Template for building a Business Case
This section provides guidance on the content that will be useful to include in your business case, but it will likely need to be adapted to the structure used in your organization’s template.