
Jake Bickford is a Web Archivist at The National Archives (UK)
Several members of the UK Government Web Archive team were fortunate to attend iPres 2022 in Glasgow, and we were all struck by the emphasis on the climate crisis and our community’s urgent need to address it. A particular highlight for me was James Baker, Rachel MacGregor and Anna McNally's workshop The Climate Crisis and New Paradigms for Digital Access, which challenged participants to identify concrete changes we could make to reduce the environmental harm caused by our work. This theme ran throughout the conference and several of the other interventions are summarised in Matthew Addis’s excellent blog post. We returned home determined not to leave these ideas behind as we resumed our normal routine.
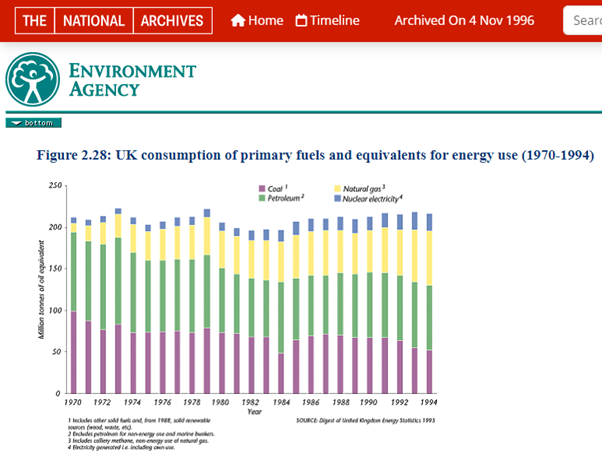
Energy use chart from one of the earliest sites preserved in the UKGWA: the Environment Agency's State of the Environment Report from 1996.
The scale of the task can seem daunting, and while wider systemic change remains necessary, we have spent the last year working to try to embed environmental concerns in our everyday practices. Some of these changes have been relatively straightforward and are analogous to good practice that people will be familiar with from their daily lives. For example, we make extensive use of cloud computing to run our internal crawl and Quality Assurance systems, and simply making sure these systems are switched off after use can result in noticeable environmental and cost savings. As well as encouraging users to do this manually, we have also implemented scheduled tasks to automatically switch off selected AWS instances outside working hours, while others are switched off automatically when their CPU usage is below a specified threshold for a set period. We also make use of regular Right Sizing reports to ensure we are making efficient use of our cloud computing resources.

Detail from the Energy Saving Trust website, captured in 2014, with the slogan “reduce the electricity you use and cut your bills”.
A more complex issue, that will be familiar to other web archives, is the problem of ‘crawler traps’. These occur where part of a website, for example a calendar, generates a very large – potentially infinite – number of pages with different URLs, even where the content is effectively the same. As our crawler sees these as different resources, it will keep on trying to capture the ‘new’ pages, potentially leading to it capturing a large amount of erroneous material, effectively wasting computational power and storage as it does so. Crawler traps can also make the archive less complete, as crawls sometimes have to be force stopped when they are caught in a trap, rather than being allowed to finish ‘naturally’. The erroneous and duplicated content can also clog up search results, making the archive harder to navigate.
Depiction of a Web Crawler or ‘spider’ from a Science Museum blog, captured in 2019.
Naturally, we have always tried to identify and avoid crawler traps wherever possible, but this has been given new impetus by our emphasis on sustainability, and we have set up a new process for dealing with them more systematically. Our partners at MirrorWeb, who perform the bulk of our captures, identify unexpectedly large or lengthy crawls as they come up, these are reviewed by our team, force stopped if necessary, and tagged in our issue management system for further investigation. We use a Python script to match this information with our up-coming crawls for the month and these are added to our crawl review backlog. The backlog items are then assessed in a bi-weekly workshop where, in small groups, we work through the crawl logs looking for evidence of crawler traps and working out the best regex patterns for blocking them, while still retaining relevant content. Using a workshop format for this task helps us to build skills in the team, share knowledge, and come to a consensus on what we can safely block. When a new reject regex pattern is applied to a crawl configuration, the next scheduled crawl is tagged for additional QA, to make sure the pattern has worked and that there have been no unintended consequences.
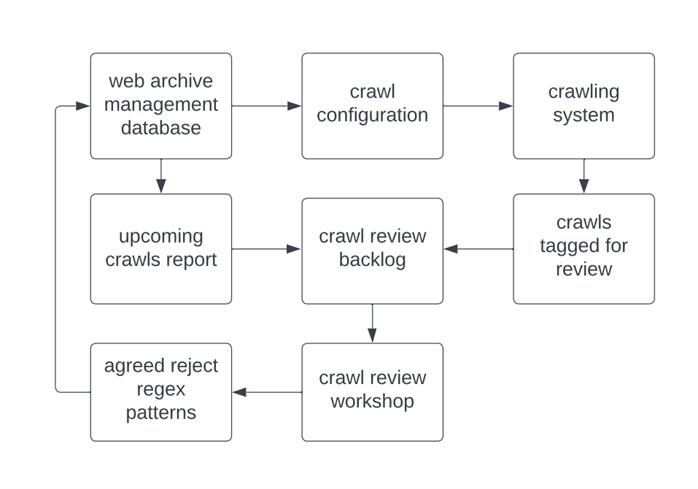
The crawl review process.
This is necessarily an iterative process, and as our priority remains making the most complete capture of the record possible, we tend to be cautious in what we block. Sometimes the same sites will come back several times for review, either because the pattern we applied hasn’t completely solved the crawler trap, or because, now the site is no longer being force stopped, the crawler is actually finding new traps in previously uncaptured content. But each time we look at a site, we refine the regex patterns, and get closer to the best possible configuration. A good example of this is our work on the National Railway Museum site, where the crawler was persistently getting stuck in the filters of the site’s ‘What’s On’ section. After several interventions, the crawl size is down from 145 GB in August 2022 to 4.4 GB in August 2023, while the number of URIs crawled is down from 2,094,025 to 20,964.
Decarbonisation exhibition from the National Railway Museum's 'What's On' section, captured September 2023.
Of course, these are small steps, and there is much more we want to do in future. A priority for me is working on a more systematic way of measuring the overall impact of our interventions, and finding ways to proactively identify these issues, as opposed to reacting to them as they occur. Other members of the team continue working to optimise our use of cloud resources, and we have also recently been discussing new approaches to capturing large datasets, that have the potential to significantly reduce the resources required. It is also important to note that this work is not taking place in a vacuum, our partners at MirrorWeb have recently significantly increased the energy efficiency of the crawling process at their end, through a move to ARM-based architecture and a new ‘crawl on rotation’ process. We also continue to be inspired by what others are doing in this space, such as the Archives and the Environment workshop held by the National Archives and the School of Advanced Study, and the University of Loughborough’s Digital Decarbonisation project, brought to our attention by a recent ARA event. Despite the progress that has been made over the last year, we recognise that we are still only at the beginning of a difficult and complex journey, but we hope that it is one that we will be able to continue, with the support of the digital preservation community.