
Micky Lindlar is Digital Preservation Team Leader at Technische Informationsbibliothek (TIB).
A few weeks ago I watched the recording of Helen Hockx-Yu’s excellent presentation on “The obsession with checksums”. In one of the slides Helen talked about “A matter of where to spend energy”, listing her top 5 priorities. One of those priorities is “overlooked things that have lead to data loss”, e.g. “not collecting content”. This really reminded me of the current work we – that is TIB’s digital preservation team – are doing around e-journals and completeness of metadata as well as content.
You might ask yourself now “what does digital preservation have to do with completeness checking and why should I care?”. Life is easy when you interact with a data producer who signs responsible for the completeness of a deposit. But what if you’re tasked to interact with a repository that you harvest data from? Or if you deal with really large deposits (e.g. more than 5 million articles)? And, as a collecting institution, do you blindly trust a manifest given to you by a publisher or do you need to cross-check? Things were easy in the analogue days. The library would receive a journal issue, all articles would be contained within that printed publication and at the end of the year all issues would be bound together in a volume. Not today, my friend!
Where’s the rest of the title!?
Just one example of things that have kept us busy: We were tasked to harvest and archive open access journals relevant to TIB’s subjects from the Hindawi website. We’re the National Subject Library of Science and Technology – so naturally articles relevant to our collection profile are bound to contain formulas. Yes, even in the metadata. While Hindawi has an OAI interface that can be used to harvest descriptive metadata in Dublin Core, we soon discovered problems with descriptive metadata that contained formulas.
The formulas look great on the article website (see Image 1) – but that is because the formula is actually contained in an svg image while the rest of the page is HTML text. The Dublin Core output via OAI, on the other hand, does not deal so smoothly with formulas. The original formula “M[x]/G1,G2/1” becomes “MX/G1, G2/1” and you don’t need to be a mathematician to figure out that those two formulas are not the same. In other cases, formulas with special characters are completely missing in the OAI output, making the title information incomplete.

Image 1: Screenshot of article website. The formula in the title is displayed via a svg image
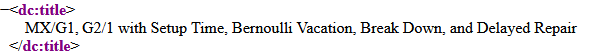
Image 2: The same formula as in Image 1 looks very different in the OAI metadata output
We are currently addressing this issue by extracting parts of the descriptive information from the full text xml instead of from the OAI output. In the Hindawi use case, the full text xml files capture formulas in MathML, which can be included in the Dublin Core value via a CDATA wrapper. Not the prettiest solution, but most certainly complete!
That’s a lot of data! Is it complete!?
In 2019 the German Projekt DEAL and the publisher John Wiley & Sons, Inc. signed the so-called DEAL-Wiley-Agreement. The agreement includes approx. 1,500 journal titles to be preserved in a dark archive by a responsible entity, in this case: TIB. 1,500 journal titles break down to approx. 5 million articles which break down to approx. 52 million files (pdf, full text xml, images, and supplements). I have to say that Wiley has been an absolute pleasure to work with and they gave us a nice inventory file alongside the deposit. The inventory file breaks down each journal title into number of articles on issue level, furthermore indicating which articles contain full-text as PDF and which don’t.
Sounds perfect, right? So where’s the problem? First off – cross-checking that large of a deposit requires a bit of time, brain cells and scripting. But is checking the delivered content against the inventory file enough? At the end of the day a large publisher is just a data warehouse as well – and can they guarantee that their data dump is actually complete? Based on our lessons-learnt with Hindawi we are currently digging deeper: e.g., looking for gaps in issue numbering and checking if full-text xmls indeed contain full-text (which is especially important if XML is the only representation on the article).
Is that really our responsibility!?
“But wait!” you might say, “Shouldn’t the publisher ensure that everything is delivered?”. That question is as old as “shouldn’t the software developer ensure a bug-free code” or “shouldn’t the tools produce only valid files”. Of course in an ideal magenta-colored-OAIS-world the producer would always know what they deliver, and would tell us, and we could check against what they claimed. But what if our producer is a platform – like in the case of Hindawi – or a really large data warehouse at a publisher that pushes data to libraries or organizations like Portico?
As digital archives we have a responsibility towards current and future generations. Surprisingly, completeness checking is something that is typically “assumed to be there” but not often addressed in digital preservation discourse. At the same time a lack of thorough completeness check can result in inadvertent data loss. To circle back to Helen – I agree that we need to invest more energy on this!