
Euan Cochrane is Digital Preservation Manager at Yale University Library.
As part of the EaaSI program of work we are aiming to make it as easy as possible to use emulation for long term digital access. One goal we’re trying to achieve is to enable users to automatically open digital objects in their original interaction software. We hope this will break down barriers to the use of emulation and preserved software in long term access contexts.
We currently have a prototype of the Universal Virtual Interactor (which is what we call the tool that automates the automated opening process) that uses file format information and other metadata to match digital objects to interaction software. It assumes that a file matching a specific file format signature (when scanned with a format identification tool), should be opened with the software for which that format was the default, and which was available when the file was created. Even then it reports multiple matches and attempts to order them by best fit/most likely to be “original” (based on dates, etc).
While this process works, it doesn’t always result in the “best” software being matched to the files. This happens for a number of reasons. Firstly files can be created by software in formats that weren’t the default for that software. It can also be the case that the software can create those files in a way that adheres to the file format standard, but structures them in a way that means only the creating software (or it’s related interaction-software counterpart) can fully present the information the user of the software attempted to capture when saving the files.
This means that processing a file through our current UVI algorithm might result in the wrong content being made available for interaction to a researcher.
The fix for this is fairly simple in concept, but complex in execution. We need to identify the interaction, and/or creating applications of files and multi-file objects directly.
Fortunately, to do this we can copy the method used by the file format identification tooling that already exists. We can create signatures that identify the creating or interaction applications of objects and use software like DROID or Siegfried to identify those application signatures automatically. Where we can only match signatures directly to creating applications we can follow that by manually linking the creating applications to the appropriate interaction applications in a registry that can be looked up by the identification tool. Fortunately the interaction applications will normally be the creating applications (e.g. Microsoft Word is normally the best interaction software for files created with Microsoft Word).
Application signatures can be identical in fundamental structure to file format signatures. They are patterns to be identified in files or sets of files, that uniquely identify the specific application that should be associated with the file(s). They are so similar to file format signatures that it’s possible to use existing tooling to identify the applications by shoe-horning application signatures into their existing configurations. For example here is a screenshot from an AutoCAD .dwg file opened in a hex editor:

You can see the string “AutoCAD 2000” highlighted in the text decoded from the hexadecimal string. This indicates that the file was probably created by AutoCAD 2000 (I also happen to know that the file was created by that software) and this string may be a signature for other files created by the same software. In addition, below are screenshots from two versions of the http://archives.govt.nz/rendering-matters-report-results-research-digital-object-rendering">Rendering Matters report I researched and wrote while at Archives New Zealand.
Word Version 14.0000
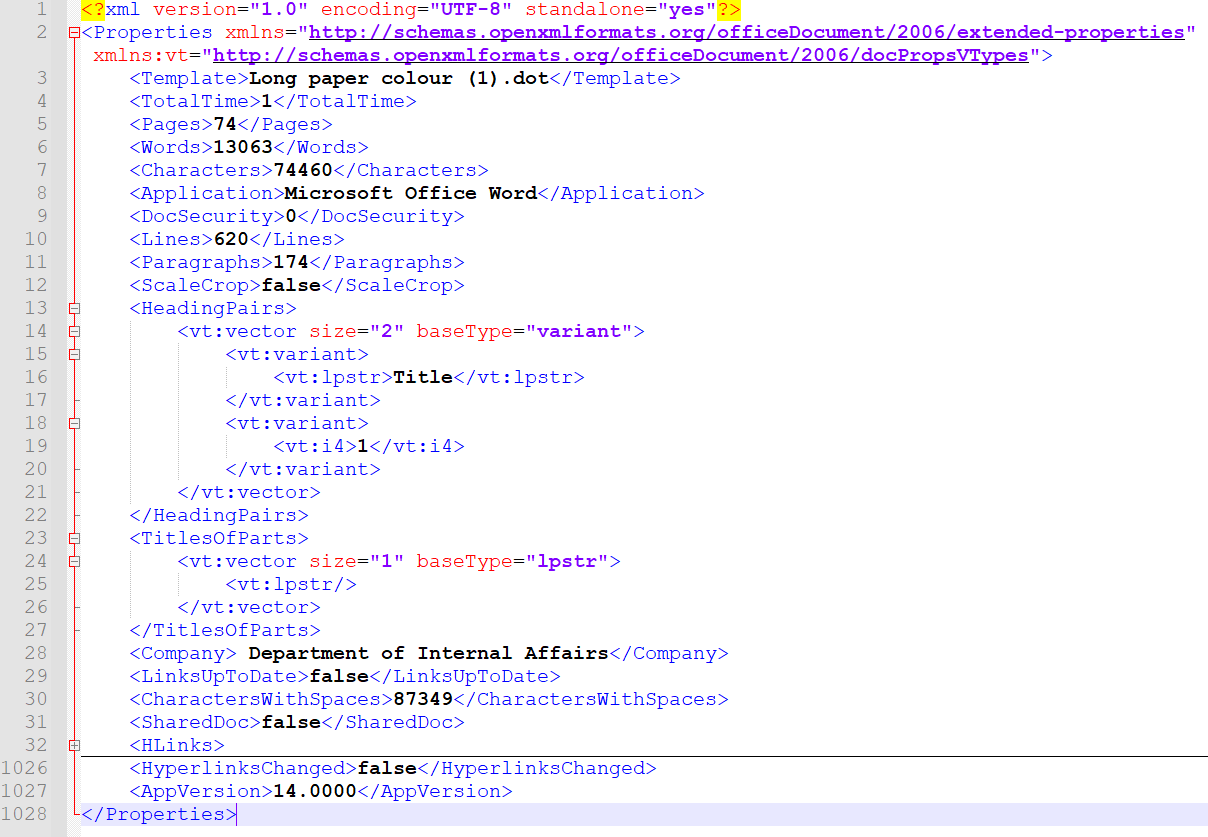
Word Version 16.0000

The first is from the Office Open XML (.docx) file as downloadable from the link above. The second is from the file opened then saved in the latest version of Microsoft Word. The screenshots are taken from inside the docProps/app.xml file from inside the .docx zip container (with the “HLinks” section minimized for brevity).
I was able to use these unique, identifying strings to create a signature that can be used with DROID to identify “Microsoft Office Word 14.0000” as the creating (and interaction) application of files that match the signature. To do this I followed the incredibly useful guide for creating container signatures that Ross Spencer wrote here (thank you Ross!). I converted the identifying strings to hex code by opening the app.xml files in a hex editor and copying that, then used the useful tool that The National Archives (TNA) PRONOM team provide here to create well formed DROID signature XML code. I added this and a dummy “Microsoft Office Word 16.0000” “file format” (creating/interaction application) entry to example signature files following Ross’s guide, and then added them to my installed DROID directories (this was tricky, I found the most successful method was to find the files in Windows and overwrite them with the new ones, keeping the filenames the same). You can find the signature files I created in github here.
So the idea of creating and using signatures to identify interaction applications works in this case. Having done a little more basic research, looking into various types of files, it appears to be at least as broadly feasible as file format signatures seem to be. However to implement it at scale we need a few small and large things to exist:
1. We need a database for software and creating application signatures. At a minimum, we need a central database for software versions and their signatures. PRONOM does offer some software information but it is fairly minimal and does not have the concept of a creating application signature.
2. We need to change existing file identification tooling to support application signatures. Having recently worked with Ross Spencer, Dr. Katherine Thornton, and Richard Lehane to make changes to Siegfried to support integration with Wikidata data, I’m optimistic about this. While it will take significant work, the existing tooling already “works” in principle so we shouldn’t need to start from scratch. One example of a necessary change will be in the signature file structures. These are the files that record the signatures that the identification tools use. Currently the DROID-formatted signature files don’t allow for matching multiple files with different MIME types to the same format (or in our case, application). This is because it doesn't make sense when identifying file formats as files can only (generally) have one mime type at a time. However multiple files with different MIME types may have the same application signature. I wasn’t able to find any two signatures for files with different MIME types that matched directly in my preliminary research however I did discover this example:
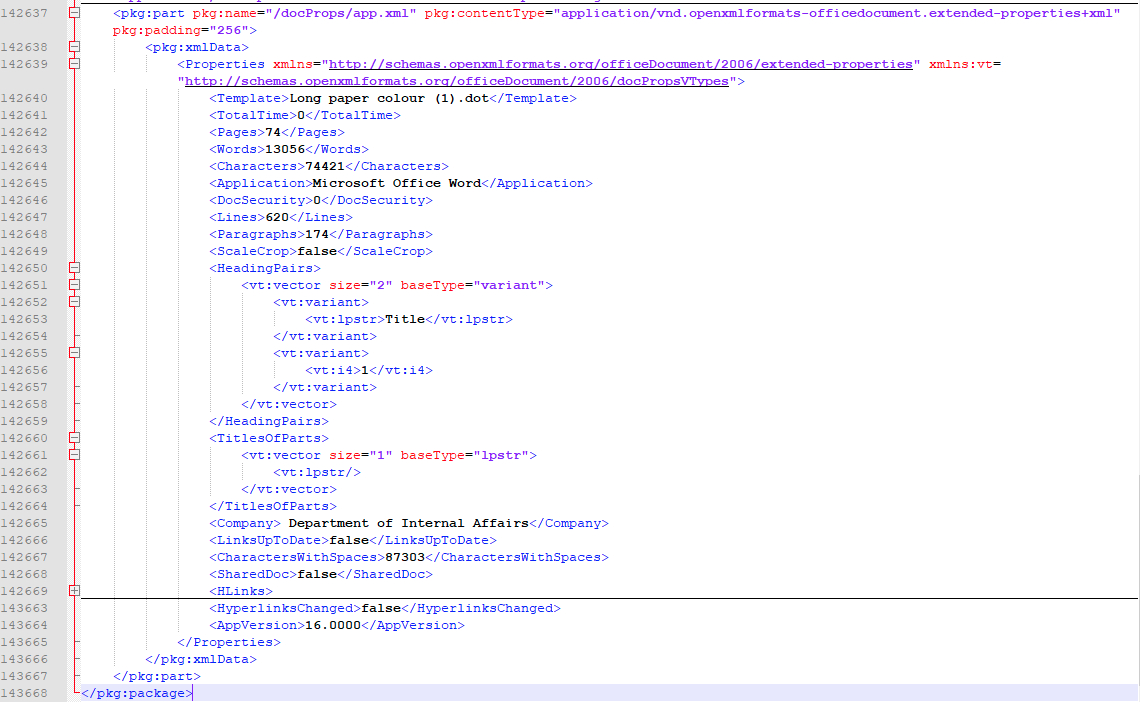
The screenshot is of the relevant part of a version of the Rendering Matters report saved as a “Word XML document” using Microsoft Word version 16.0000.
The unique strings (<Application>Microsoft Office Word</Application> and <AppVersion>16.0000</Appversion) that make up the creating application signature look identical to the unique strings in the xml file inside the Office Open XML (docx) container format. This is as we should expect. Wherever possible it makes sense for creating applications to use the exact same methods to identify themselves when writing out files, regardless of the format. However it is definitely a difference between creating application signatures and file format signatures.
3. We need to identify and record application signatures. It has taken years to populate PRONOM, the TrID definitions, and the other file format data sources now represented in Wikidata. It will likely take years to do the same for creating application signatures. There is potential for using tools like TrIDScan to automatically create signatures from sample files created automatically with the EaaSI interaction API when that becomes available but it will be a big task however it is undertaken.
4. We need to match creating applications to interaction applications. As discussed, we may only be able to find signatures that match creating applications directly. In such cases our database of software will need to associate creating applications with appropriate interaction applications for each file format. This requires a new data structure that relates creating applications to interaction applications and file formats. The database will have to enable users to look up creating applications of a specific format and find the appropriate interaction application for files with that format as created by that application. As discussed, this will normally be the creating application, but not always so populating this information will be vital to ensuring the efficacy of this matching process.
Other issues and questions
-
We may never match original software. Even if we manage to find signatures of the code that created a file, it may not match with the actual creating application. For example, it seems like multiple versions of the same software may use the same code to write a file with a particular format https://digitalcontinuity.org/post/7325561455/mining-application-documentation-for-file-format. However each application, if used as the interaction software, may interpret the file differently. In these cases, if we can’t find a signature that matches the interaction application directly, identifying the creating application may only result in our being able to provide a list of possible “appropriate” and compatible interaction applications, in which case it would be up to the user to pick one or try them all.
-
Should these be identifiable signatures or file-properties? In discussions with colleagues some have suggested that the creating or interaction application of a digital object is a property of the object’s file(s). They’ve felt that these are properties that should be extracted from the file(s) with a property extraction tool, rather than signatures to be identified in the file(s) using an identification tool. There are a few reasons why I think the proposed signature-oriented approach makes more sense.
-
There may not be file-format properties to be extracted. In many cases the associated application(s) may only be represented by signatures in the files that are inadvertently included as identifying signatures as a by-product of the way the creating software writes-out files, not as a deliberate file property.
-
It makes sense to include interaction application association in the same places in digital preservation processes as we do file format identification. It is more important than file format identification for evidentiary purposes (as using the most “original” interaction software is the best way to be sure the original content is also being presented to users), and it is as important as file format identification for general preservation risk-management purposes. In most digital preservation systems file format identification is used to assess the risk of the organization’s ability to interact with files and initiate a process to migrate content from the ingested files into new files with different, more interactable, formats. So firstly, the ability of software to open files at all is being used as a measure for long term preservation/access risk in those situations, which is problematic as being able to open files doesn’t mean an application is the right one to open them in (I can open all the files in our digital preservation system using a hex editor, but that doesn’t mean it’s the right application for them). But secondly, another way to mitigate that risk (rather than migrating content into new, different files) is to acquire and associate the appropriate interaction software with the object and it’s files, or to ensure long-term access to such software (e.g. via a access to something like an EaaSI network). It makes sense to identify and address this risk in the same places in the workflows as we currently do as they are the same risks.
-
-
How accurate is good enough? Many of the example files cited above were created with a version of Microsoft Word that adds the “<AppVersion>16.0000</AppVersion> version declaration to many of the files that it creates. However when I navigate to the “Account” interface in the application it provides different and/or additional information about the specific application that is in use:
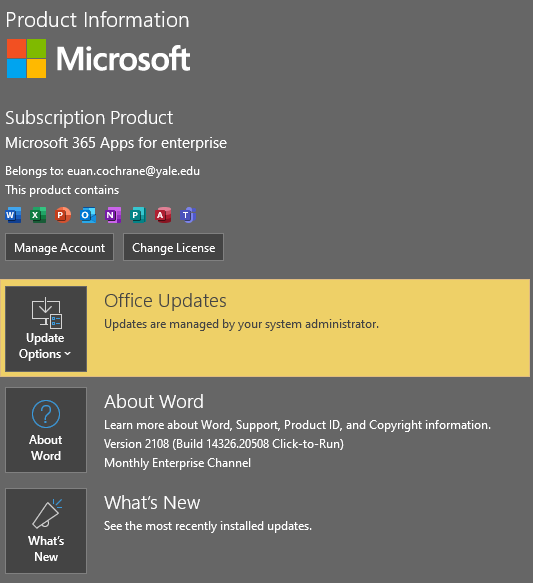
In this area in the interface there is information stating firstly that it is a “Microsoft 365 Apps for enterprise” version, and secondly that it is “Version 2108 (Build 14326.20508 Click-to-Run)”. Neither of these pieces of identifying information are included in the files created by the software. Since I don’t know anything about the relationship between these three descriptions I am left wondering whether the version information written into the files that the application creates is accurate. It may be that version 16.0000 is the public version number for the internal build 14326.20508, and that all previous builds between the previous public version and version 16.0000 were never published publicly. This kind of information about the relationship between the three version numbers may be able to be sought from the publisher directly or deduced by looking at the history of the two different information sources in previous and future versions of the application. Regardless of this specific example, it does raise some questions:
-
Which version numbers should we be tracking and associating with signatures?
-
Do we need to track version number aliases (e.g. 16.0000 = build 14326.20508)?
-
If there is a public version 16.0300 (as there is for Microsoft Excel), or build 14326.20509, do we need to track these and create new signatures for each?
I personally tend towards a preference for more accuracy and more data rather than less. But this will be something for the community to decide over time.
So there are many unanswered questions and there is a lot of work ahead to make this happen. However it seems like both the right time to start on this, and the right idea for this year’s World Digital Preservation Day. The theme this year is “’Breaking Down Barriers’ is an opportunity to demonstrate how digital preservation supports digital connections, unlocks potential and creates lasting value”. I’m optimistic that the ideas proposed here have the potential to do all of this. And with technology like Wikibase and Wikidata now becoming normalized and accepted by the community, we seem to be well placed to address this challenge and answer these questions over the coming years.
Comments
(here is the link to Ross's tweet https://twitter.com/beet_keeper/status/1456401209007517708)