
Tom Storrar is the Web Archiving Service Owner at The National Archives.
The COVID-19 pandemic has been an unprecedented challenge for The National Archives’ Web Archiving Team. In the six months since our last blog post, we have continued our efforts to build a definitive record of the government response to the first pandemic of the digital age. Our three-pronged approach, consisting of regular in-depth archiving of core websites, complimented by broad crawls across the government web estate, working closely with our suppliers, MirrorWeb, and daily captures of interactive content with the excellent Webrecorder/Conifer tools have now matured and become routine.
This has not been without its technical challenges. With each of these “prongs” we have had to change the way we work, and rapidly: not only to working remotely, but also to new technology and to the speed with which content has been updated or published. This has prompted us to create new approaches to archiving content and to accelerate innovations that we had already started to develop before the pandemic. For example, we need to ensure that every member of the team has available to them their own version of Webrecorder/Conifer in this remote scenario. So far we have achieved this using virtual machines, which is quite a change from just a year ago, when we were taking turns capturing content from a single machine in the office!
And there is the continued innovation required to capture an important service - Public Health England’s COVID-19 Dashboard. Our aim has been not only to capture daily snapshots of the service, but to make this activity sustainable for the team. Early on in the pandemic, manual processes were required, as conventional web archiving technology was incapable of archiving this dynamic content. We have built from this to where we are now, able to run entire captures of the dashboard daily and automatically, using a script that simultaneously archives the data via the service’s API responses and the html resources that make the pages viewable in your browser, then saving it all to WARC files for access and preservation. This is the first time that we have used a hybrid API and crawler-based approach for a sustained period of time.
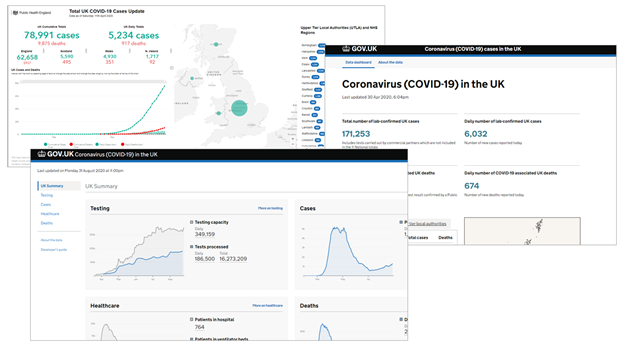
IMAGE: The COVID-19 Dashboard in the UKGWA, https://coronavirus.data.gov.uk/, as at, clockwise from top left: 12 April, 1 May and 1 September
Since April 2020, the UK Government Web Archive (UKGWA) has grown by around 25TB, and with several updates to the public service in this time, you can see for yourself the impact this effort has had on the number of snapshots we have made - see GOV.UK and NHS.UK
We intend to continue and build on the advances we have made this year and use the approaches we have developed to address future challenges. We plan to improve how we do this, for example by broadening our toolset so that we can address further challenges, such as difficult social media platforms, and by moving from virtual machines to cloud-based services to increase the resilience of the capture technology throughout the team.