


















































































































































Gareth Knight is Research Data Manager in the Library & Archives Service at the London School of Hygiene & Tropical Medicine.
Health research often involves the collection and processing of data from human participants. This data often must be made available to others for the purpose of validation and further development, which makes it essential that it remains usable over time. In this blog post, I will outline some of the steps that may be taken to curate quantitative data held in STATA format.
This topic has previously been explored in a fantastic DPC blog post by Jenny O'Neill in 2017 (https://www.dpconline.org/blog/quanititative-file-formats-for-preservation), however, I will be putting an institutional spin on the topic.
Health context
The London School of Hygiene & Tropical Medicine (LSHTM) is a public research university that specialises in the field of public health and tropical medicine. Between 2012-2015, it undertook a Wellcome Trust project to enhance data management practice among researchers. The strong focus upon health research and relatively small size of the institution made it possible to provide researcher support that would not be feasible at a larger scale. As a result, the Library & Archives Service was able to work closely with research projects to help them to address their data preservation and sharing requirements.
Curating STATA datasets
The institutional data repository, LSHTM Data Compass (https://datacompass.lshtm.ac.uk/), was launched in 2015 as a platform that LSHTM researchers could use to curate, preserve, and share research data and other resources necessary to reproduce research findings. Take-up of the repository has grown significantly during the past few years, with more than 1500+ data outputs currently recorded in the data repository.
Many health researchers upload quantitative data sets encoded in STATA format (.dta), a proprietary binary format produced by the STATA software package (https://www.stata.com/).
STATA is a statistical software tool produced by StataCorp LLC that is widely used in the research community. It provides a command line and graphical interface through which users may perform various types of processing and analysis upon their data, and can be extended through the use of third party tools written by researchers themselves.
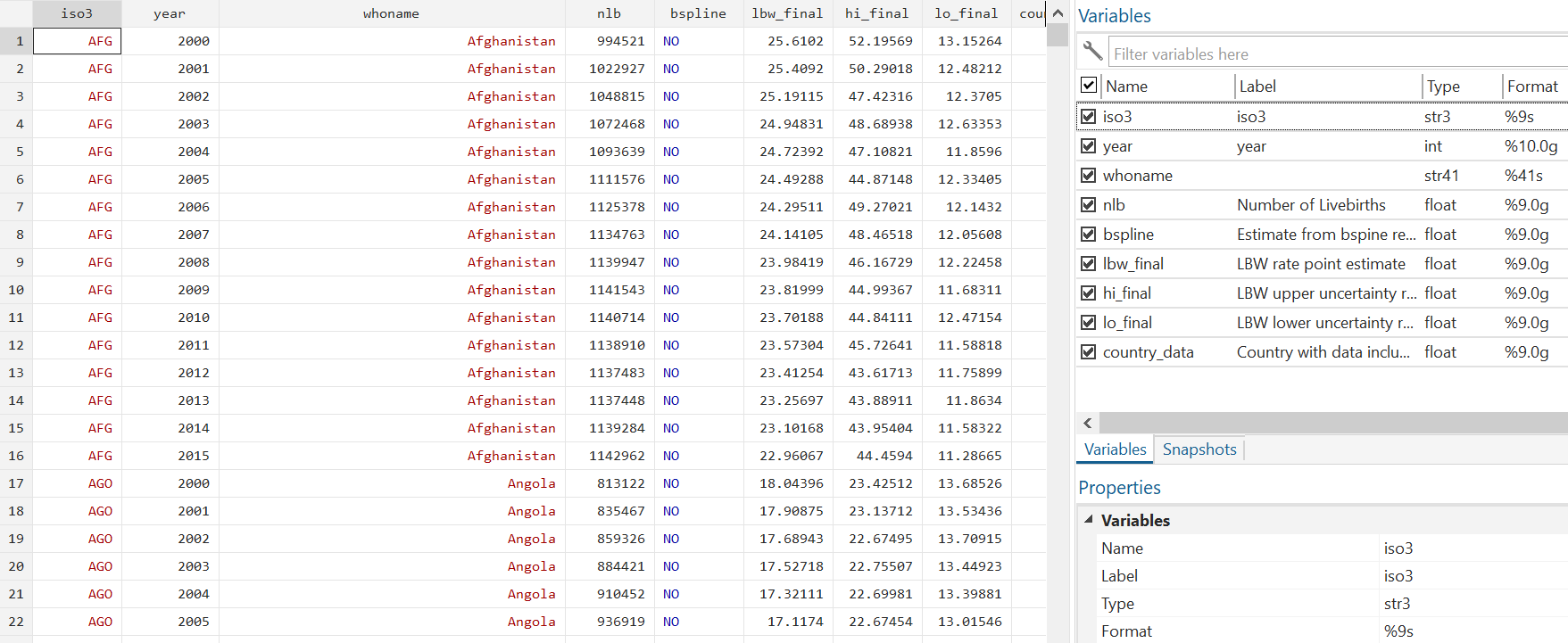
A STATA dataset produced by an LSHTM academic. This dataset is available at https://doi.org/10.17037/DATA.00001090
Proprietary formats often have negative connotations for digital preservation. However, the Library of Congress Format Description (https://www.loc.gov/preservation/digital/formats/fdd/fdd000471.shtml) notes that STATA is listed as a preferred or acceptable format by many data archives, a format description is publicly available, and the format uses XML-style mark-up that can be viewed using a simple text viewer. This enables users that do not have the STATA application to work with STATA files. For instance, R users are able to read and write STATA .dta files using the ‘Foreign’ package (https://cran.r-project.org/web/packages/foreign/index.html) hosted on The Comprehensive R Archive Network.
Although the STATA format is well-used in health research, the use of application-specific formats remains a barrier to entry – it cannot be assumed that a current or future user will have the relevant software or knowledge to handle a .dta file. For this reason, we export STATA data sets to tab-delimited text (TSV) for preservation and comma separated text (CSV) for access. Variable-level checks are performed to ensure that variables have been exported correctly – all data values are present and displayed correctly. CSV is used for access purposes, due to MS Windows being setup to automatically import .csv into Excel or similar (quotations are placed around variables where commas are present, to ensure they’re processed correctly).
Data documentation
A benefit of working with STATA, in comparison to generic tools such as MS Excel, is that it provides the ability to create variable-level documentation and embed it within the data set. This simplifies the preservation process, at least in principle, by encouraging data creators to clearly describe each variable (so a researcher will know that a ‘dt’ measurement relates to Diphtheria) and enable code to be clearly labelled (e.g. 0=Tested negative, 1=Tested positive, 2=Not tested, 3=Not applicable). However, it does not guarantee that a data creator will populate these fields with meaningful information. A lot of time associated with preparing data for preservation is often spent on enhancing data documentation. Actions performed can vary from clarifying acronyms, to mapping survey questions to the resultant dataset.
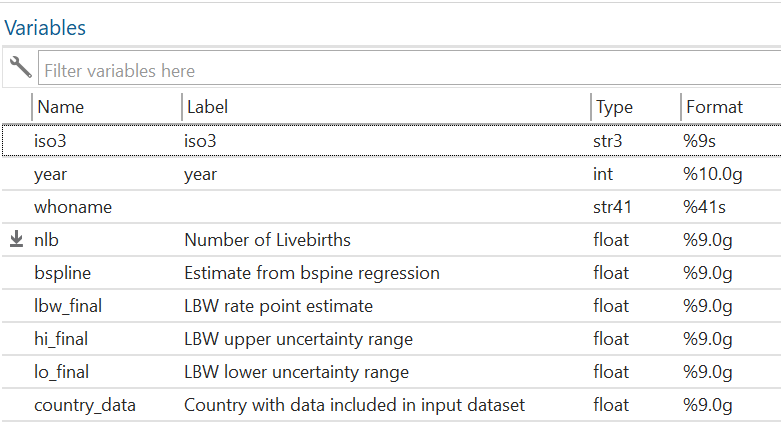
An example of variable-level documentation.
We currently preserve variable-level documentation contained within a STATA data set by exporting it to a separate Excel .xlsx using CodebookOut (https://ideas.repec.org/c/boc/bocode/s457811.html) and subsequently converting it to tab delimited text (TSV) for preservation and HTML for access.
The separation of data and documentation into separate files presents a risk that an end user may download a data set without the associated document. However, this approach is often essential for data sets published via controlled access, where researchers must specify the variables they wish to analyse when applying for access.
STATA processing scripts
A third component of a STATA data set is the processing script necessary to reproduce an analysis. These are often held in a separate STATA-do file – a plain text file with a .do or .ado file extension - which contains a set of processing commands. At the time of the LSHTM data repository’s launch in 2015, many LSHTM researchers did not consider it necessary to provide these processing scripts with their submission. However, we actively encourage researchers to make these scripts available, either as a supplement to their dataset or a distinct research output, in order to enhance research reproducibility.
Summary
STATA is a proprietary format, but its widespread adoption makes it useful from a preservation perspective. The close relationship between data variables and documentation ensures that each measurement is clearly defined in many cases. Similarly its support for third party tools allows content to be exported to alternative file formats.
We still have a lot to learn in terms of the most effective approach for preserving STATA data sets - text-based formats, such as TSV and CSV, provide a simple method for ensuring long-term access to content. However, there is a recognised limitation in that they separate data from documentation. Future work will explore the benefits of providing STATA data set in alternative formats, such as the DDI metadata standards.