


















































































































































Dr Santhilata Kuppili Venkata is Digital Preservation Specialist / Researcher at The National Archives, UK
The file format identification problem has been of interest for quite some time in the areas of digital archiving and digital forensics. Many researchers are working to find a solution to this problem. While most of the work is done to identify files with binary file formats, not much work is found to identify the file type of plain text files. In this digital era, files are often generated in an integrated development environment where each document generated is supported by multiple files. These include programming source code, data description files (such as XML), configuration files etc. For digital preservation, it is important to understand each of these supporting files correctly.
Contents of the supporting files are often human-readable. i.e they can be opened as plain text files using a simple text editor. But if the file extensions are missed or corrupted, it is hard to know how to put that file to use!!
Some of the existing research work used Natural Language Processing (NLP) techniques such as pattern matching of n-gram contiguous sequence models. Even though these techniques needs the program to be written in a specific style only. They fail to differentiate files when the target file types have almost similar structures (for example, Java and C). We need to generate file features and classification models in such a way that they describe file types distinctly. To address this problem, we kick started the research project: 'Text File Format Identification' at The National Archives (TNA). Our initial prototype makes use of machine learning algorithms and can identify five formats: Python, Java, .txt, .csv, .tsv.
How a simple plain text file can create confusion?
Here is an example to make things clear. The file is missing its file extension so we have to identify the file type from its contents only!
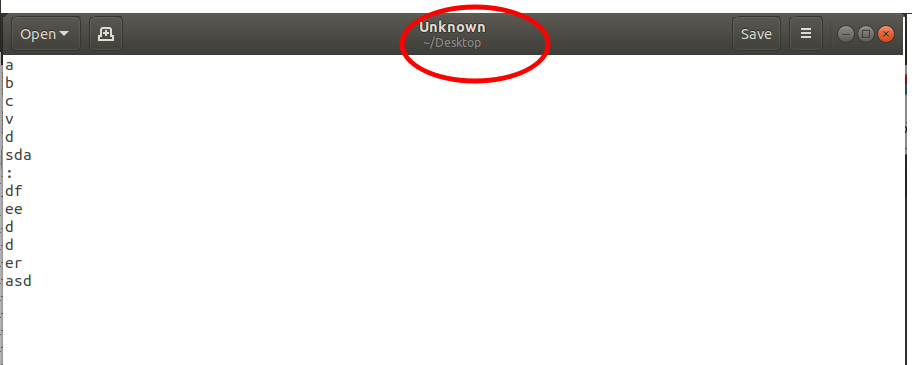
Figure 1: A sample text file
The file shown here contains some characters from Roman alphabets written in a column. At first glance, one would think that this must be a simple exercise to typewriting characters in alphabetical order. Someone familiar with the Unix environment cannot rule out the possibility of this file being a part of a bash script/commands. Still worse when the experience cautions us, what if something is dangerously encrypted into this innocent set of characters! I know, it is far from reality… but one can not rule out the possibility! Nevertheless, the question remains, how can we make use of the file even though it does not make any sense at the moment? If we have thousands of such files, it is impossible to examine each file physically, so we need to automate the process of file type identification.
How Big is the problem?
TNA is expecting to receive thousands of digital records from government departments in the near future. To understand the enormity of these transfers, we have cloned all publicly available GitHub repositories of the Government Digital Service (GDS) and TNA. Out of 1457 public repositories, we found more than 410,000 files which could be opened using a text editor. These files represent 928 file types in total. It means, with the current trend of file generation, TNA has to process these many files and file types regularly. Figure 2 shows a graph of those file types which occurred at least 500 times in our sample dataset.
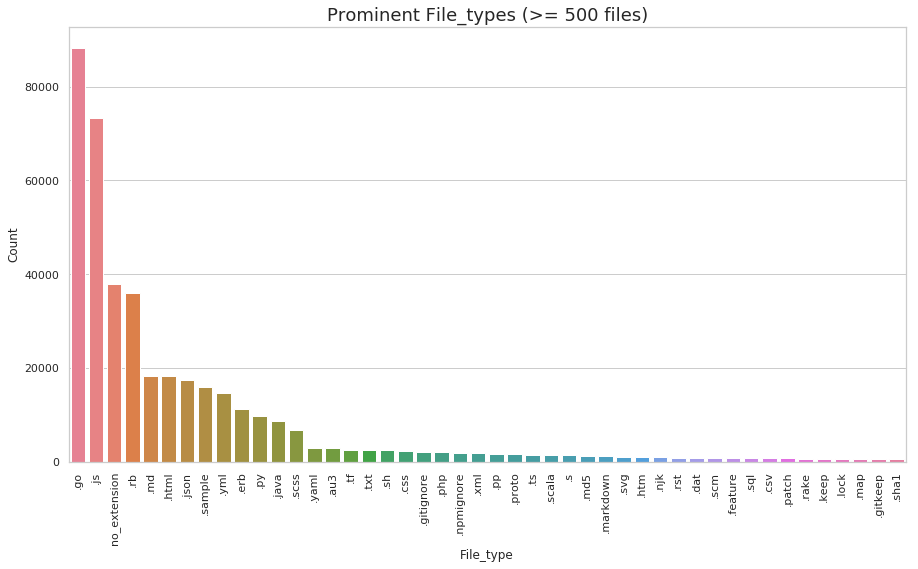
Figure 2: Some prominent file types found in the repositories
Our starting point
It is a huge task to build a generic classifier that recognises all 928 file types. So we grouped them initially into 14 categories. Figure 3 shows the distribution of 13 file types and the number of files in each category. The 14th category is a collection of all other file types that cannot be categorized into any of the other groups. From the DROID reports generated in the past, programming codes and text files are the major file types received by TNA. So as a starting point, we concentrated on a small subset consisting of five file types. These file types include two programming source code file types (Java, Python) one text file types (.txt) and two data file types (.csv and .tsv).
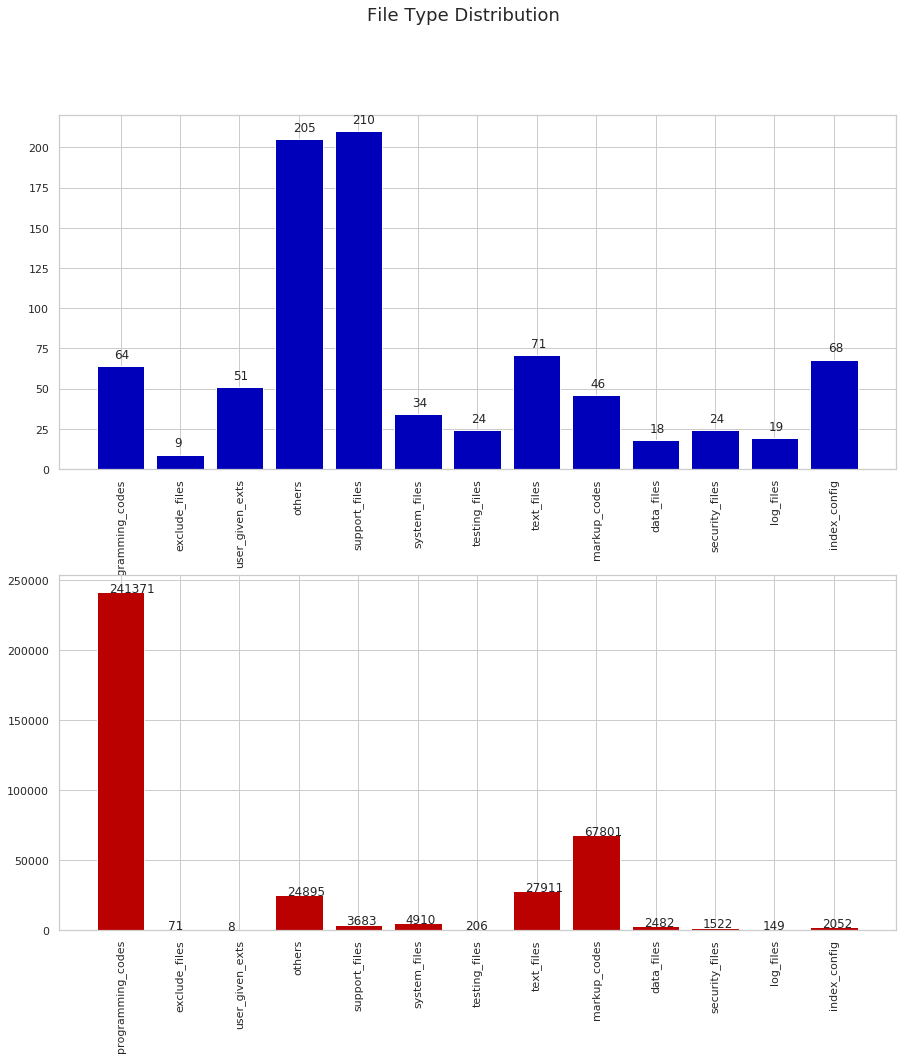
Figure 3: Distribution of file types
Conclusion
File format identification for plain text files is a daunting task for digital preservation. At TNA, we have kick started the project to identify Plain text file format identification. We have already come up with our first prototype. The details will be published in our next blog.