
Yvonne Tunnat is Digital Preservation Project Manager at Leibniz Information Centre for Economics in Germany
When you think about risky file formats, the PDF format is not the first one that springs in your mind isn’t it?
Instead, you might think of old word processing software for C64 or amiga 500, when 'windows' were just some glass to look through. Or, a more recent typical risky file format scenario: the dozen flavours of exotic file formats your institutional scientists give you on a regular basis, insisting that these formats are the only acceptable ones in their specific community and migration to some standard format known to normal population is just too much to ask for.
For us in the Digital Archive of the Leibniz Information Centre for Economics in Kiel/Hamburg, lacking files with such interesting formats – maybe luckily – the danger of our archiving reality lies elsewhere.
Only around 6% of our archived files are in PDFs. The other 94% are easy formats like JPEG, TIFF and all kinds of non-binary-text files, plus a long tail, which can be ignored for now. However, so far the PDF files are causing 94% of the trouble. Easily.
6% of the files causes 94% of the trouble
It does not help that the PDF format is in theory very well equipped for long-term-sustainability. But we do not archive them in a theoretical world. Our world does not play by the rules of theory.
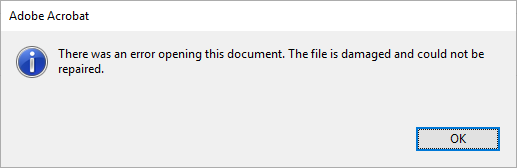
Of our almost 200,000 archived PDF files, for more than 15% JHOVE comes to the conclusion: not well-formed.
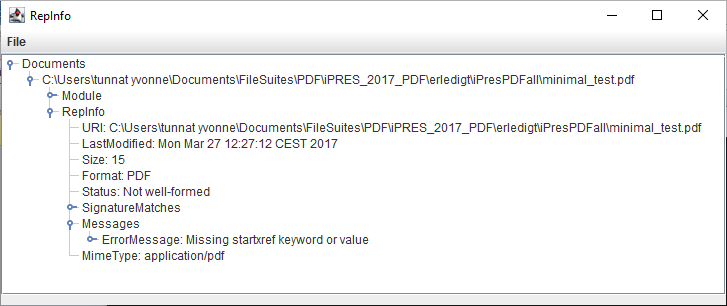
And JHOVE is not even always right. There are some false positives (false alarms), but even more worrysome are the false negatives: faulty PDF files which JHOVE does not mark as malformed. More information on this topic can be found in the iPRES-2017 Paper of Micky, Carl and me (http://files.dnb.de/nestor/weitere/ipres2017.pdf) and in my OPF-blogpost from 2017 (https://openpreservation.org/blog/2017/12/19/jhove-the-one-and-only-pdf-validator/ ).
Nobody thinks in earnest that the PDF file format will be obsolete any time soon. Quite the contrary. We think they are robust and will last over time, especially PDF/A. I am quite sure, a perfectly valid and well-done PDF is very sustainable and nothing to worry about in the forseeable future. Just save the bits, add good metadata and you will be fine.
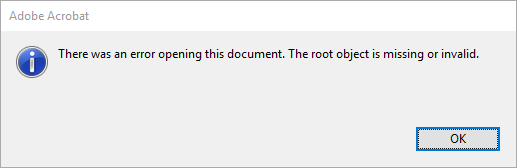
Besides, they are also very mighty: they can deal with text, graphics, photos, can be accessible for disabled people, can contain all kinds of other mime types including software and video, and there is hardly a reasonable limitation to size (although if bigger than 2 GB, some viewers start to have trouble). But this mightyness comes with a prize. The PDF file format is very complex. While the TIFF specification contains of 121 pages and is understandable for the average mortal archivist, the PDF file format specification e. g. for PDF 1.7 starts with 756 pages for part 1 and if you add the 41 references and dependencies, you can easily end up hiring someone just to try to understand the PDF file format – and that’s only one flavour, there are 39 others; and we do have 18 of them in our Digital Archive.
Furthermore, there is a plethora of PDF creators out there and even more original formats that can can be converted into a PDF, plus the users that convert these files to PDF. This leads to an insane number of possible errors a PDF can have, which are not allowed by the PDF specification or lead to problems when viewing the PDF, now or in the future.
Of course, that’s not new. You already know that.
So, how do we deal with that?
We have bought a professional software to migrate our variety of PDF flavours to PDF/A-2b. So far, the success quote is 96%. We are constantly analysing the error messages of the remaining, not convertable PDF files and improve our migration parameters to achieve a higher percentage, more often than not with the help of the support team of the software. Because, however, they ARE getting paid for dealing with the PDF file format full-time. This leaves a pretty long tail with PDF files we cannot repair – at least not yet.
Passwordprotected PDF files
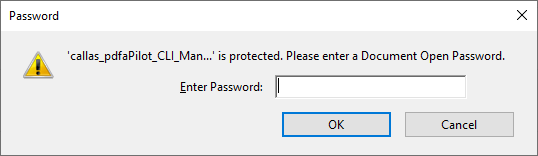
But we do have a bigger problem still.
Of our almost 200,000 archived PDF files, 3,524 are password-protected.
At least, our users can open and read them without a password, but migration is impossible due to security settings.
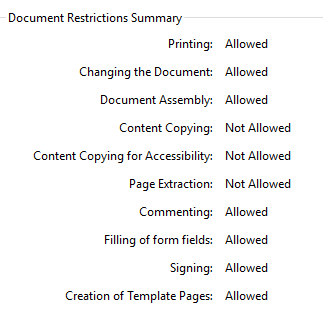
So these files cannot be migrated to PDF/A or any other "better" PDF as long as we do not have the permission of the data producer, which is a long and cumbersome workflow due to the many different data producers and the lack of direct contact to them.
PDFs too broken to be examined
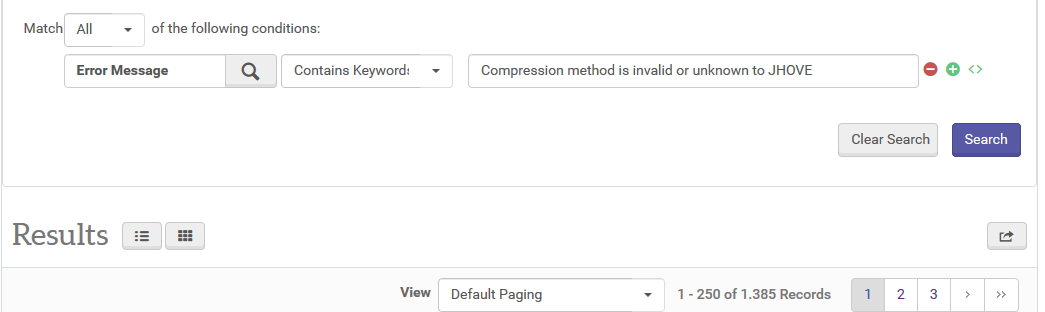
Worse still, there are 1,385 PDF files, which are too invalid to be examined by JHOVE and an unknown number of them is password-protected, as a sampling has already shown.
JHOVE exits the examination without the extraction of any properties with the message "Compression method is invalid or unknown to JHOVE." There are other tools, of course, which are able to detect password-protection even in these faulty files, however, they are not integrated in our system yet. Plus, even after we have detected which files are affected, we are not allowed to perform any kind of repair. As long as we are unable to contact the data producer, they just sit in our Digital Archive, proven to be faulty and therefore, you know, just a little bit dangerous.
Read more...