















































































































































A Note from the Editor, Sara Day Thomson
As the coordinator of the DPC’s Web Archiving & Preservation Working Group, it has been my absolute pleasure to work with some of the most enthusiastic, creative, and persevering professionals in the field. The community of archivists, curators, librarians, researchers, and enthusiasts who do the work of capturing and preserving web resources has always displayed a collaborative spirit and a willingness to try new approaches and learn from each other.
The coronavirus pandemic has truly and profoundly put that spirit to the test, and the web archiving community has not disappointed.
‘The speed, scale, and level of interest in participating in this collective effort have been remarkable and have no comparison to previous collaborative endeavours,’ Jefferson Bailey from Internet Archive attests. ‘It is a great testament to the community's ability to work together.’
Over the last week I’ve been in touch with a handful of the professionals at the front lines of this effort to archive the global experience of coronavirus. In a series of blog posts, I’ll share their insights into this urgent undertaking to capture the world’s response to coronavirus (Covid-19) online.
Last week we heard from the UK Web Archiving team about their approaches to capturing the deluge of content emerging every day on the coronavirus outbreak, including harnessing the crowd to identify web resources as soon as possible.
‘We are clearly facing one of the severest threats in our lifetimes, certainly one of the fastest and most clearly devastating,’ writes Nicola Bingham, Lead Curator of Web Archives at the British Library, ‘and while Librarians might not (yet) be members of the Emergency Services, we feel the act of recording the outbreak as it plays out online is a crucial one.’
The Web Archiving Team at the UKWA aren’t the only team of first responders rushing to capture the tsunami of coronavirus-related content inundating the web. The scale and urgency of this pandemic as it plays out online is in some ways obvious. Anyone with access to the internet has witnessed the speed at which information changes and the wall-to-wall coverage the pandemic receives from news media.
As Silvia Sevilla from the EU Publications Office describes: ‘The big difference in the current situation caused by the coronavirus / Covid-19 [compared to past major events] is the speed at which the news is produced and the large rotation of content. If we want to archive all this, we need to make a continuous effort in identifying and capturing content.’
Ben Els from the Bibliothèque nationale du Luxembourg (BnL) echoes that point: ‘It is very important to pay close attention to the news and social media, since lots of new websites and information platforms are being announced every day.’

The sheer volume of web content related to the pandemic is overwhelming for a passive consumer. Imagine the effort required to identify, evaluate, prioritize, select, describe, capture, check, and share as much of this content as possible. And there is no time to spare. Without regular, rapid response, these web resources may well disappear or become swamped in the deluge.
Trying to select and capture content at warp speed is only one of the challenges facing web archivists. The urgency and global significance of the outbreak has also put extra pressure on other typical web archiving challenges. For example, understanding the privacy implications of capturing social media and the ability of available tools to capture non-standard forms of web content.
Ben Els discusses one such challenge in relation to capturing social media content: ‘A lot of discussions and solidarity activism happens in dedicated groups on Facebook, but since these are closed groups, where everyone can join and share their questions and opinions, we are not sure whether we should try to capture those as well.’
The conundrum of whether or not to archive Facebook Group pages is well-established. The privacy restrictions imposed by Facebook to protect users also inhibit archivists from capturing content on public or semi-public pages. Researchers, notably social scientists, have used Facebook Groups to interact with communities, obtaining formal consent from users in order to use data from these pages. The process of gaining permission from every individual in every relevant Facebook Group would be, in the context of web archiving the coronavirus outbreak, extraordinarily labour-intensive, needless to say, prohibitive.
However, the way communities have used social media platforms - to reach out to each other, organise support for vulnerable neighbours, promote verified information about the virus - demonstrates one of the most remarkable responses to the pandemic. Archiving only official channels such as news media, government, and health organisations only captures part of the coronavirus story.
In addition to the challenges posed by social media platforms, web archivists face other technical obstacles. Silvia Sevilla explains one such difficulty: ‘… most of the content [we’re trying to capture] is produced in news sections that sometimes use POST requests, which are not always easy to capture. We are trying to find the best way to archive these contents.’
The difficulty of keeping web archiving tools up-to-date for capturing constantly evolving web technologies has been a challenge for web archiving from the beginning. No sooner has a tool been updated or created than a new web platform emerges that confounds it. However, the coronavirus outbreak intensifies this challenge because of the heightened urgency of documenting such a critical event.

Also, if anyone reading this can help with capturing content generated by POST requests, please get in touch!
The prognosis is not as bleak as it seems. There is a bright, shining light at the end of this dystopian tunnel. Despite the challenges, the web archiving community has shown truly inspiring teamwork and collaboration.
One notable example of this teamwork is the collaborative collecting initiative led by the International Internet Preservation Consortium (IIPC) and Archive-It (by Internet Archive). The IIPC and their collaborators have been identifying and capturing resources since mid-February and will continue to add new content as the pandemic evolves and global responses adapt.
The current collection can be found through Archive-It's online portal. So far, this global team of web archivists has captured 2573 sites in 30 languages related to the coronavirus outbreak and counting!
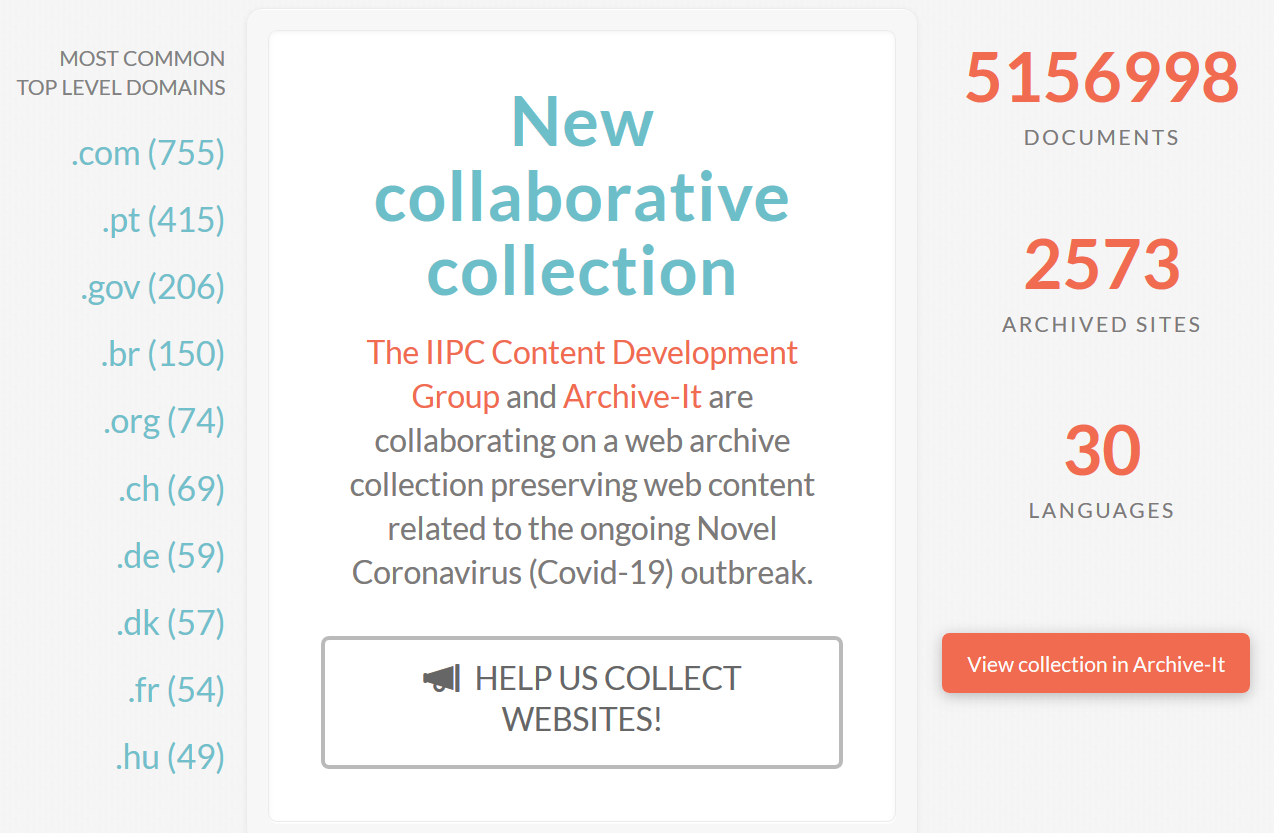
But there is still a big job to be done! How can you help? This collaborative team has issued a call for contributions. They are looking for:
‘Web content from all countries and in any language is in scope. High priority subtopics include:
- Coronavirus origins
- Information about the spread of infection
- Regional or local containment efforts
- Medical/Scientific aspects
- Social aspects
- Economic aspects
- Political aspects’
To nominate a web resource related to the outbreak of coronavirus / Covid-19, use this submission form.
When asked how the DPC community can help, Jefferson Bailey, one of the instigators of this collaborative effort, responded: ‘The DPC community can help by contributing in any areas possible - curation, metadata, infrastructure, access - and by leveraging their networks to find ways to collaborate and share resources. And we can all continue our advocacy for the importance of open access, data sharing, collaborative archiving, and preserving born-digital materials.’
No organisation has been untouched by the outbreak of coronavirus. If you’re looking for more information about how to archive the web resources from your organisation or community related to coronavirus - there is lots of help!
Maria Ryan, Web Archivist at the National Library of Ireland advises ‘anyone who is thinking about web archiving to spend some time carrying out research. Communities like the DPC and the International Internet Preservation Coalition can offer support and guidance on how to carry out web archiving.’ (Thank you Maria! We’re doing our best!)
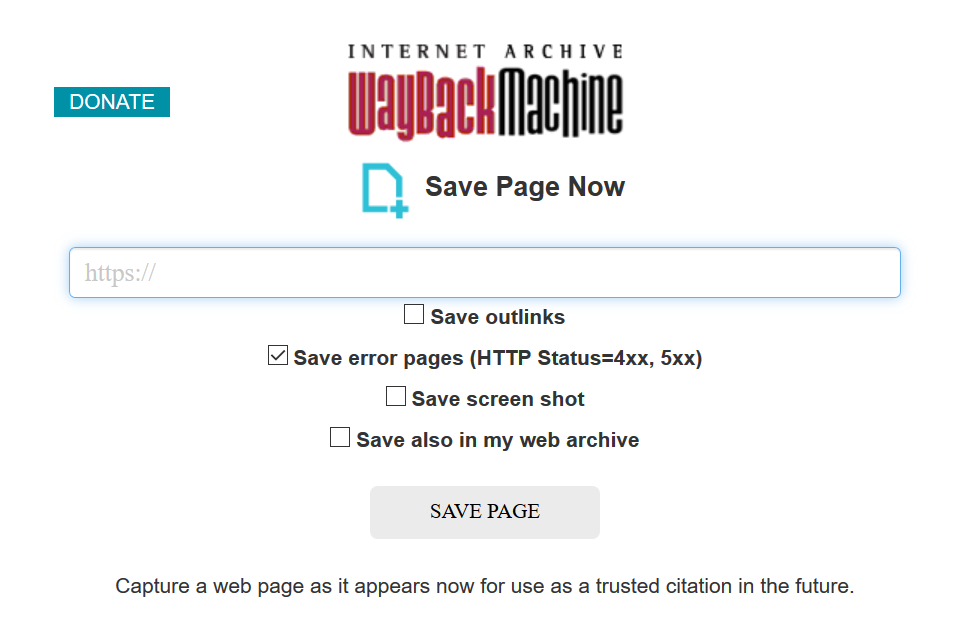
Almost every web archivist involved in this blog series has advised using the Internet Archive’s ‘Save Page Now’ feature to quickly capture individual pages (and I concur!). Simply enter the URL you want to capture and click ‘Save Page’.
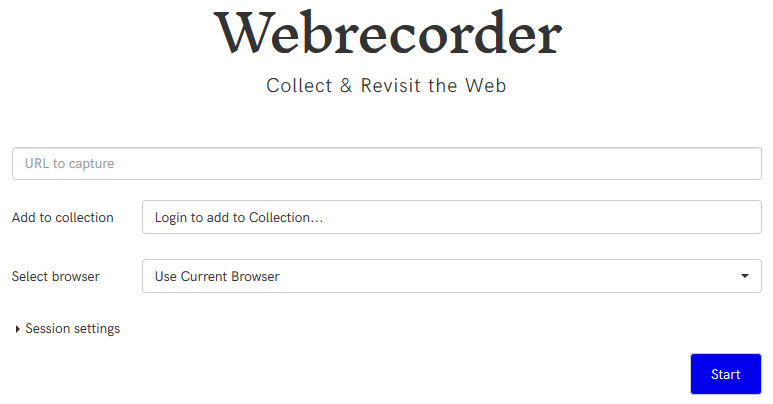
If you’re looking to capture a broader range of interconnected resources, especially if you want to capture interactive pages or social media, you might consider using the open-source tool Webrecorder. Sign up for an account and start browsing the web in capture mode. The developers of Webrecorder have created detailed guidance for getting started quickly.
Other tools for DIY web archiving can be found on this community-maintained list.
To jumpstart a programme of web archiving at your organisation, you might consider getting in touch with the Internet Archive. ‘The Archive-It service is working closely with many of our 600+ institutional partners and is excited to work with any institutions new to web archiving,’ Jefferson Bailey has relayed, ‘to determine how best to offer free or subsidized additional web archiving services to help meet the challenge of those wishing to archive web content related to COVID-19's impact locally. Feel free to contact us.’
Under the circumstances, it can be difficult to think past the present moment. However, as we’ve seen in the experiences of web archivists around the world, there is an important group of professionals who have their eye on the future. This tireless community is busy documenting new developments as they unfold so that one day, when the crisis has abated, researchers, governments, and health organisations can look back and learn.
In the next installment of this series, we’ll hear from the UK Government Web Archive Team and how they have implemented a 3-pronged approach to document the UK Government’s response to the coronavirus outbreak.
In the meantime, don’t be a stranger. If you have a particular question about web archiving or your own coronavirus web archiving story, let us know in the comments down below.
A huge heartfelt thank you to all the busy web archivists who took time out of their superhero days to share their experiences with me. Especially thank you to Nicola Bingham Lead Curator, Web Archiving, British Library, Ben Els, Digital Curator, Bibliotheque national de Luxembourg, Silvia Seville in Web Preservation at the EU Publications Office, Jefferson Bailey, Director, Web Archiving & Data Services, Internet Archive, Maria Ryan, Web Archivist, National Library of Ireland, Claire Newing and Tom Storrar, UK Government Web Archive, UK National Archives, and Abbie Grotke and Team, Web Archiving, Library of Congress.