








































































































































Claire Newing is Web Archivist at The National Archives in the UK
2021 is the year the UK Government Web Archive came of age. On 4 November we celebrated the 25th birthday of our oldest resource - this archived version of the Environment Agency website. Of course it shared its birthday with World Digital Preservation Day 2021 so a double excuse to celebrate.

Archived version of the Environment Agency website captured 4 November 1996
On top of that we are also celebrating the 18th birthday of our web archiving programme.
In 2003 we entered into a contract with Internet Archive to archive UK Government websites and the UK Government Web Archive was born. Internet Archive also kindly provided us with copies of UK Government websites they had captured since 1996 to backfill our collection.
Since the inception of the programme we always contracted out the technical aspects of the capture and access parts of the archiving process to a specialist provider. However, we have always undertaken some aspects in house and now run a program which we consider to be a ‘hybrid’ in several respects. For example, copies of all WARC and ancillary files are transferred to us for permanent preservation in our tape library (known as the ‘Dark Archive’) alongside our other digital collections. In this post I am going to focus on the hybrid process we are using for capture.
Like most other large web archives, we have always used the Heritrix crawler. Heritrix is great at capturing traditional websites at scale but less successful with certain types of interactive content. When a new open source crawler, Webrecorder, which claimed to ‘capture interactive websites and replay them at a later time as accurately as possible’ became available in 2016 we were keen to experiment. We set up a local version and had some good results when targeting challenging content. One of our earliest successes was capturing the functionality of the ‘EU Quiz’ which formed part of the UK Government EU Referendum website and was removed from the live web shortly after the referendum took place.

Archived version of Take the EU Quiz - captured 20 June 2016
Initially we stored the WARC files produced by the Webrecorder crawls in house but after we started working with MirrorWeb we began to send them over to merged with the main collection. At first the number of Webrecorder WARCs we were producing was small and targeted on (a) a small number of high priority sites which held content which could not be captured well with Heritrix. Often we captured only the problem section of the site with Webrecorder while the bulk was captured with Heritrix. (b) Single resources or small portions of sites which needed to be captured quickly to record a specific event. In these cases it was quicker, easier and more cost effective for us to capture a few resources manually using Webrecorder than to order a full crawl with Heritrix. Once the content had been captured we would send the WARC files to MirrorWeb on an ad hoc basis.
Interestingly MirrorWeb also began to use Webrecorder as part of their patching process. If missing content is found during quality assurance checks they can choose to patch it (add it to the archive) using either Webrecorder or Heritrix. However, the terms of our current contract do not cover requests to manually capture large amounts of content, or to undertake small scale captures outside of our usual crawl pipeline, so we continued to undertake larger jobs in house.
The ad hoc arrangement continued until 2020 when the COVID pandemic hit triggered major changes in our work. We found that we needed to capture a lot more content using Webrecorder, partly because websites were changing more quickly than usual and partly because important resources like the official COVID-19 Dashboard could not be captured well using Heritrix. We also started experimenting with other Webrecorder based tools to see whether they could improve capture. In some cases we found that the Conifer subscription service or a locally hosted build of Webrecorder captured content well. In other cases the Chrome extension ArchiveWeb.page produced better results. We also made use of Webrecorder Player and later, ReplayWeb.page to check replay. All the different capture services produce WARC files which can be integrated with our collection smoothly.
As the COVID-19 Dashboard expanded and became more complex it became impractical to capture it manually. We started to experiment with Browsertrix to see whether it would be possible to run more automated captures. Browsertrix is another tool developed by the Webrecorder project which automates browsers to perform complex scripted behaviors and crawl multiple pages. The experiments were successful and we have been using Browsertrix to capture the dashboard and other content daily since August 2020. The volume of content we are capturing in house has increased to around 4GB each day.
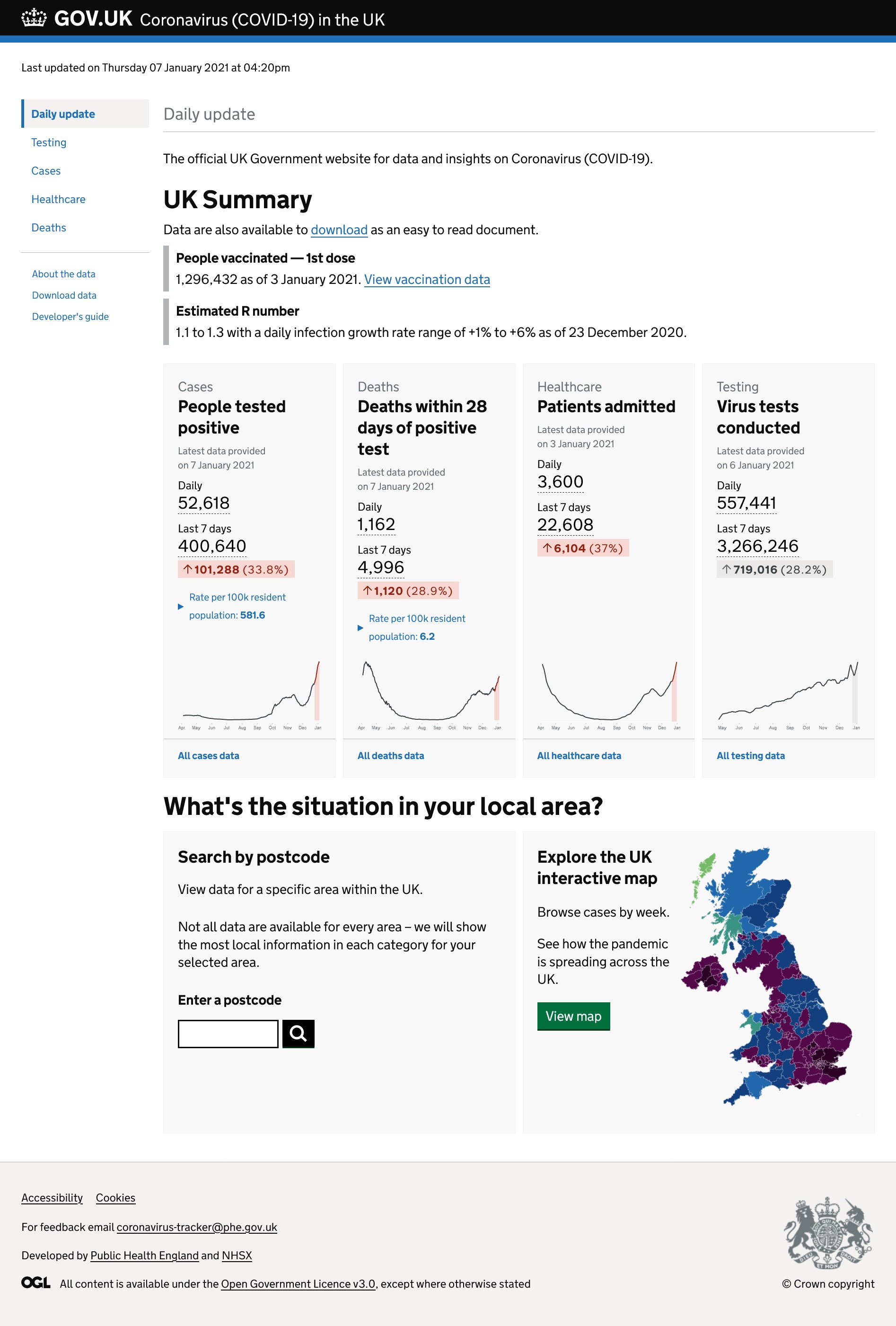
Archived version of the Coronavirus Dashboard captured on 8 January 2021 showing the data for 7 January 2021 - the first day that vaccination data was included.
Now that in-house crawls are a regular occurrence we needed to develop a process. I have listed below the steps in the process as it stands at the moment. It is important to note that it is under constant review and refinement.
-
Content is identified as needing to be captured using a Webrecorder based tool rather than Heritrix. This is usually assessed visually by our team or is noticed following an unsuccessful Heritrix crawl.
-
Content is captured using one of the Webrecorder based tools and is uploaded to our Conifer account. We open a new collection in Conifer each day and all data captured that day is added to that collection.
-
A member of our team undertakes quality assurance checks on crawls undertaken using Browsertrix by browsing them in Conifer and patches in any missing content. We find that Conifer is a useful tool for the quality assurance stage of the process as it allows us to combine WARC files captured using different tools and to either view them directly in Conifer or to export them as a single file and view them in a tool such as ReplayWeb.page.
-
When all the daily work is finished we download the collection and add it to a ‘Pending transfer’ folder in our AWS (Amazon Web Services) account. At this point the collection can be viewed in our cloud hosted PYWB (Python Wayback) instance so we can undertake more checks before transfer if required.
-
Periodically, in accordance with an agreed schedule, we download the files from our AWS bucket and sync them to a shared MirrorWeb bucket.
-
MirrorWeb merges the files with the public collection.
-
When we have received confirmation the WARCs have been successfully merged we delete the copies from our accounts and consider them to be part of the main collection.
The system is working well at present and we plan to continue using and refining it after we have stopped running many daily crawls for the COVID-19 collection.
Using the hybrid model has some difficulties. The process is currently operating outside of our long established capture pipeline so dates of capture and other information are not automatically included in our management systems. We will need to look at merging this information at a later date. Additionally, we do not currently have a reliable way of identifying which parts of larger sites would benefit from being captured using a browser based crawler - it relies on a human being noticing a problem - in future we would like to find a way to do this automatically. In general though we are happy with our progress so far and are sure that it has enabled us to capture and provide access to content which would otherwise be lost.
We will be speaking more about our use of Browsertrix at the Web Archiving & Preservation Working Group - General Meeting on 9 December 2021. Places are still available. It would be great to see you there.
Thank you to my colleagues Michael Tobin and Tom Storrar for their help with this post.