


























































































































Platform
The final approach described in this guide is the provision of computational access to collections through a platform or interface made available by the content-providing organization. This is normally a dedicated online environment where the user is able to manipulate the material within it. The infrastructure behind this approach can be quite similar to the other two, the main difference being that not only does the user have access to the data, but also access to a set of tools to compute over the data. These platforms range from very simple manipulations, such as Google Books, where date ranges can be changed, to more sophisticated setups such as tools provided in the CLARIAH media suite, which give the user the possibility to explore audio-visual material and the Archives Unleashed project which is focused on analyzing web material.
The control around these environments can vary; some make it possible for everyone to log in, sometimes you need to be a registered user. Also, it may be possible to manipulate material in the environment, but not necessarily output any results, due to copyright or other legislative reasons.
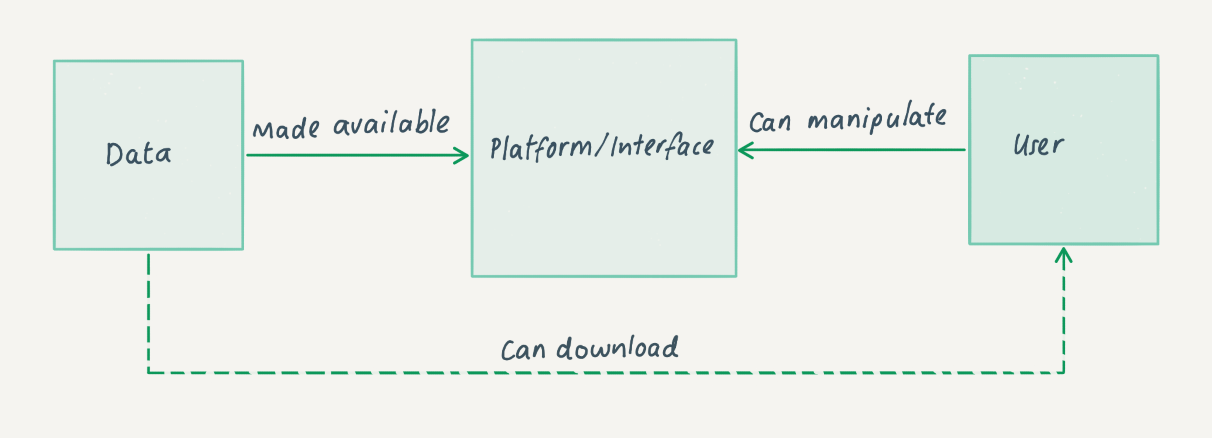
The diagram below illustrates the platform model for computational access and shows the organization making data available through a platform or interface within which the user can access and manipulate the data. The dotted line illustrates the fact that some implementations additionally offer the user the option to download the raw or manipulated data.
Users may even get the opportunity to bring in other datasets or software to work with the data on the platform, but again this may be restricted because of constraints around the material. The Archives Unleashed project is completely different in that aspect, as it only offers the tools with public domain material. This makes it possible for users to bring in their own material. However, as the project is not liable for any of the material brought into its platform, users will not be able to save any of the analyses they have carried out. An interesting paper about the Archives Unleashed project is available here: The Archives Unleashed Project: Technology, Process, and Community to Improve Scholarly Access to Web Archives.
The table below gives an overview of a number of these platforms and notes some of the implementation differences, for example:
-
Does the platform offer metadata or data (or both)?
-
Can users supply their own tools and/or data to work with in the platform?
-
Can data be downloaded from the platform after analysis?
-
What constraints or restrictions are associated with the data?
-
Who can access the platform?
|
Organization/Project |
Data/Metadata |
Bring your own software/datasets |
Downloadable? |
Constraints on Data |
Who can access? |
|
Both |
Yes |
After being checked by staff |
Copyrighted material |
Only accessible by members |
|
|
Both |
Not at the moment |
No, but derived datasets may be possible in future |
Copyrighted material |
Accessible to the public, but need to be logged in to access the full functionality |
|
|
Some public domain material as an example |
Yes, only your own material is accepted |
Yes |
Depends on user, but Archives Unleashed is not liable |
Currently only accessible to Archive-It account holders and researchers who have worked with Archives Unleashed before |