



























































































































In his most recent blog post, William Kilbride reminded us that we in the digital preservation community “cannot make the case [for preservation] on our own terms. We need to make the case in terms that our audience understand” so that “preservation becomes an intrinsically achievable goal from the outset, not something we need to tack on at the end.”
We have had some experiences recently at Portico that were very suggestive to us of ways to make the case for preservation to those outside the preservation community, and perhaps lead to some first steps to “born-preservable” digital objects.
Portico, a service of the non-for-profit organization ITHAKA, is a preservation service for the digital artifacts of scholarly communication. Portico’s original remit in 2005 – one shared by many DPC member organizations – was to develop a sustainable technological infrastructure that would support the scholarly community’s transition from reliance on print journals to reliance upon electronic scholarly journals. The need for such technological and organizational infrastructure had been articulated by and for the scholarly community (libraries, publishers, academic researchers) in a body of work dating back at least until 1996. So at least the first of William’s requirements was met.
Change, as William noted in his post, is not a bug – it’s a design feature. Ten years into the preservation of scholarly e-journals, and then scholarly e-books, and digitized historical collections, and twenty years into the print-to-digital transition, and informed by such work in our community as the 2014 OCLC report on The Evolving Scholarly Record, we realized we needed to step back and take another look at the landscape of the artifacts of scholarly communication.
What have we learned, and what has changed since the first phase of the print-to-digital transition in scholarly publication and communication? The first thing we understood is that we needed a more sophisticated notion of content – of truly “digitally native” scholarly research.
For Portico, for example, the original "what" that we were preserving was a "digital analog" of the print scholarly journal literature. It looked something like this:
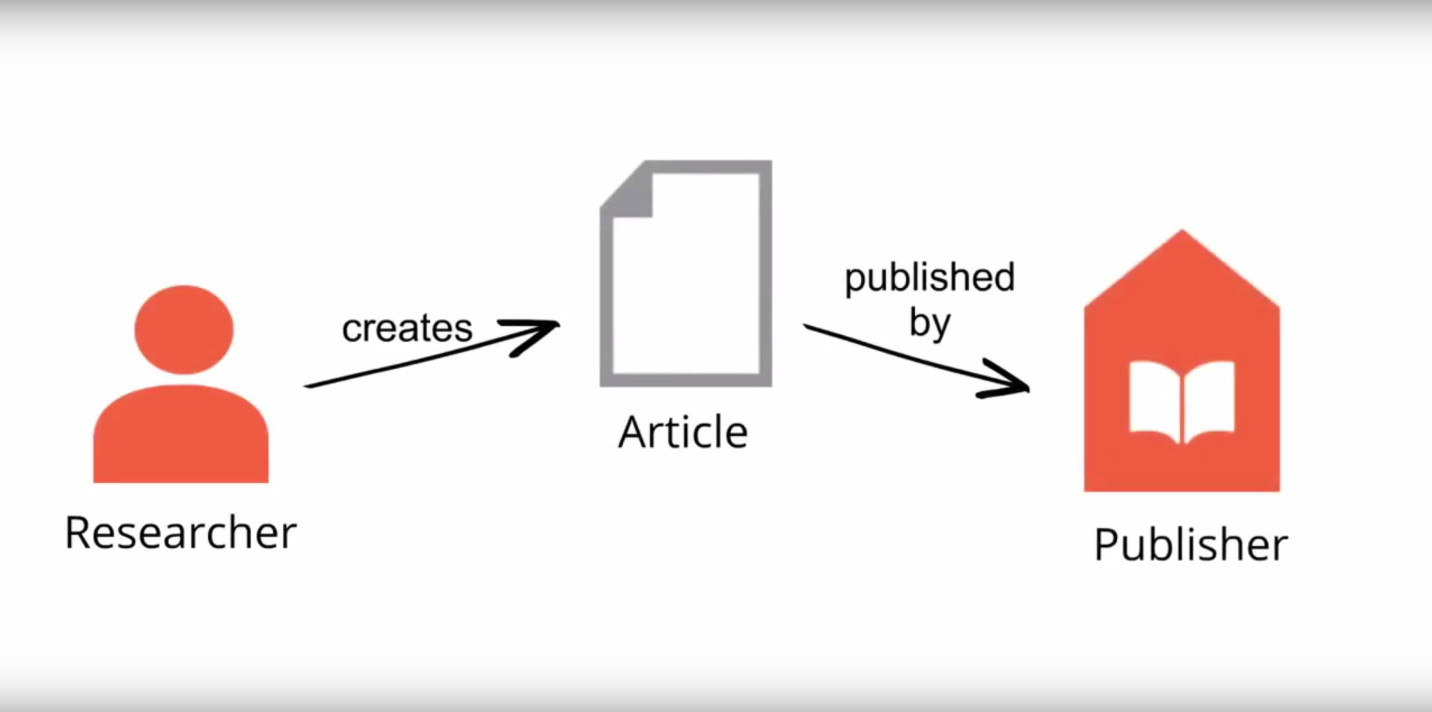
What has become increasingly clear since is that digitally native scholarly content is different. It is complex (made of both related and nested components). It is distributed, with components created at different times, and located in different places, with multiple versions among and across components. Its use is mediated (by software above all). And it is subject to expectations for different kinds of use, from what might be called "original experience" to uses unanticipated by its creators (large scale text mining of corpora of content, including the text of scholarly journal articles, is just one example).
So instead of just, say, “saving the journal article” by capturing and preserving a PDF file, with perhaps some associated metadata, what we have to first capture, then preserve, and then make accessible, looks more like the picture below: a complex network of heterogeneous objects, distributed in space, any component of which may have significant versions, the relationships among components quite complex; making guarantees of use over the very long term of both individual components, and the object as a whole, quite demanding to fulfill.
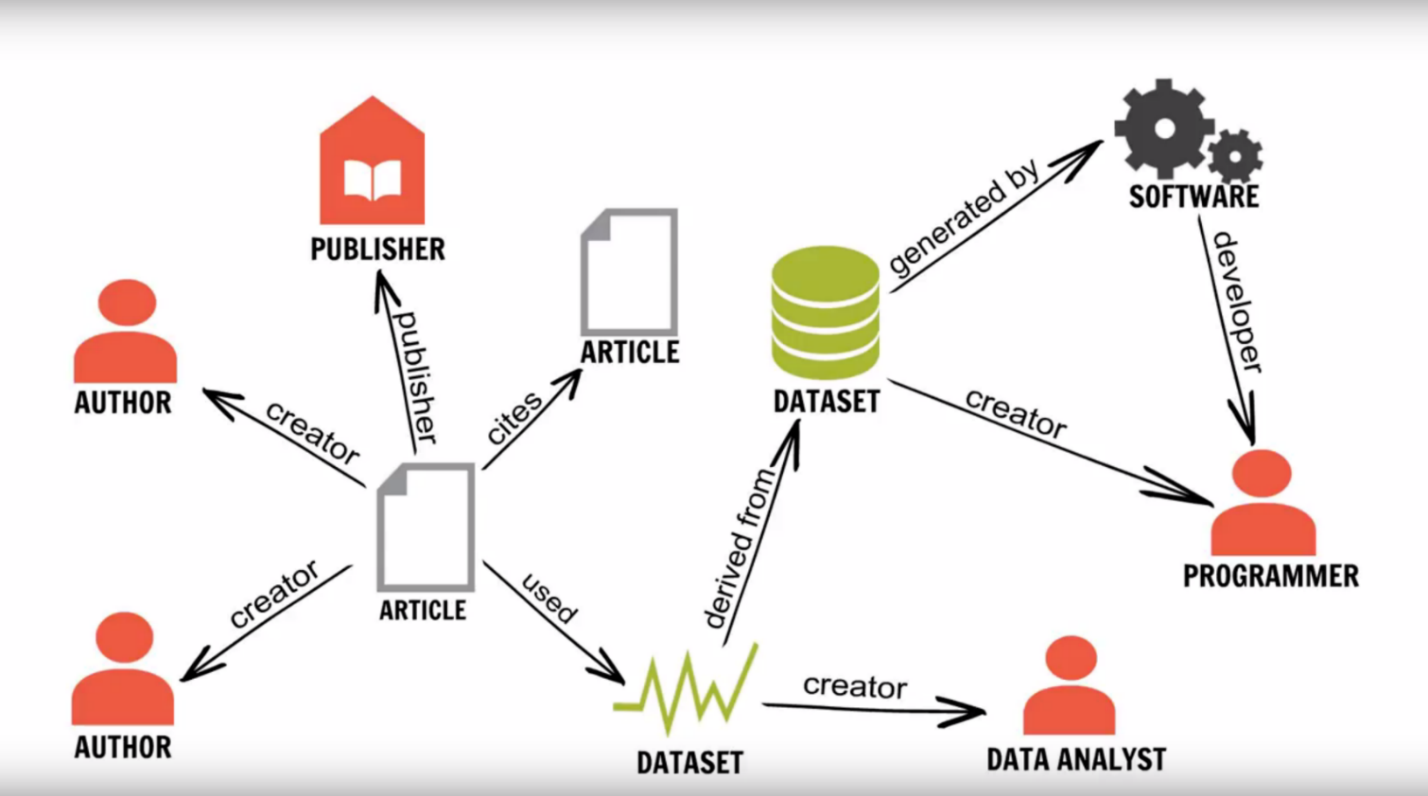
Investigating the challenges of capturing such a network of information was the intent of the RMap project. The RMap project was undertaken by the Data Conservancy, Portico, and IEEE, and was funded by the Alfred P. Sloan Foundation. Its goal was to create a prototype API and service that could capture and preserve the maps of relationships amongst the distributed artifacts of scholarly research and communications. The intent in capturing and preserving these "research maps" was to facilitate the discovery and reuse of those artifacts, to demonstrate the impact and reuse of research, and to provide, via the articulation of the map of connections amongst artifacts, the context necessary for the curation and preservation of digital research artifacts, including software and workflows
An interesting and unanticipated development that emerged from collaborations with organizations who worked with the RMap project partners was the realization of the convergence between the more than 20-year-old effort to preserve digital scholarly literature, with the demands for evaluation and curation of the now increasingly digital artifacts of experimentation and research that have arisen from what is referred to as the "crisis in reproducibility research results.” While exploring ways of integrating the capture of research maps in scholarly research and publishing workflows, Portico became part of initiatives in computer science research and publishing to establish best practices for the review of the artefacts of scholarly research, with the goal of ensuring the reproducibility and reliability of research results. These efforts include the ACM Task force on Data, Software, and Reproducibility, and a National Science Foundation-funded initiative by IEEE on the Future of Research Curation and Research Reproducibility.
How are digital preservation and reproducibility of results related? Well, what do we need to preserve a born-digital object? Hardware. Software. Contextual information (about the hardware, the software, the born-digital object).
And what do we need for reproducibility of research results in computer science? Hardware. Software. Contextual information (about the hardware, the software, the born-digital object).
The concrete analysis, tools, techniques, and organizational patterns developed in the course of solving the challenges of digital preservation mean that building the infrastructure for reproducibility of research, especially in computer science, does not have to start from scratch. The preservation community has developed conceptual frameworks (models, vocabularies, formalisms), and pragmatic mechanisms (processes and systems for content acquisition and management; persistent identification; software repositories like INRIA-supported Software Heritage project; emulation as a service developed at bwFLA and employed at Rhizome and Yale University Library; capture of artifacts and digital context, not just in the RMap project, but also in ResearchObjects) that can be adopted and adapted for the purpose of ensuring research reproducibility.
Importantly for the digital preservation community, that door William mentioned (that we might want to put a foot or two or three into) swings both ways. The tools and infrastructure developed by the research community, in the interest of ensuring reproducibility of research results, though perhaps geared toward a nearer horizon than we in preservation tend to assume, is already enriching the larger digital preservation ecosystem – with tools like ReproZip and the Collective Knowledge Framework and OCCAM and Code Ocean.
Collectively, these shared tools, techniques, and frameworks will go a long way toward making preservation something “baked into” the artefacts of scholarly research, rather than something added after the fact. And demonstrably, in helping to ensure the quality of research, they forward what William terms the goal of all of in the digital preservation community: “to have an impact on the real world, now and in the future.”
Read more...